Me
MeDisclosure: All opinions expressed in this article are my own, and represent no one but myself and not those of my current or any previous employers.
You can listen to this post here.
This might come off as me being lazy, and let's be clear here: I (rightfully!) don't get paid for this drivel, so I should be forgiven, but this post is going to have some overlap to another one I wrote, earlier this year, amongst others. But, with each passing day, we are learning more, and with each passing day, the technology continues to advance and change. New competition enters the market, while others fade away. And importantly, with each round of explaining these concepts, the discussion becomes more dialled in and understandable. That's my hope here: that I can better explain my thinking on what the important different layers of AI are, and how they fit together, and then position that discussion into a larger roadmap that includes where I believe the AI world is headed.
I'm crediting a friend of mine from back in my days in Silicon Valley with the title of this post. Let's call him Ivan, because, well, that's his name. Ivan and I caught up a couple of weeks ago and were discussing AI and the journey it's been on. He commented about how we need to now see this transition, "from poetry to prose." His comments were along the lines of how AI (for the masses) has been around for literally under two years (ChatGPT was launched in November, 2022, which set off this wildfire), and for awhile all we heard about was how it was going to replace all the jobs, how students were using it to write their papers, and how it was going to kill the music industry. I'm not sure what will happen with that, and this post isn't discussing the results of asking a magic 8 ball.

What it is about is how businesses and organisations understandably want to use AI to help alleviate tasks from their employees and as a differentiating factor and competitive edge. And most companies aren't creating music or writing homework. So "the prose" is about how we find practical applications for this exciting set of new technologies. Now is the time we move from the hype cycle to the practical usages of AI, and start to see real benefits from a business perspective. Now is the time to be a part of the shift from poetry to prose. In order to do that, we have to develop a deeper understanding of AI, and be able to recognise how the parts fit together, where the complexities lie, how the Hello, World tutorials provide us with the basics, but don't prepare us for scale or other production considerations. I want this post to help lay the groundwork for us to begin to deliver real practical value to our organisations, and to begin to unlock the promise of AI.
If you've read my earlier posts, first, thank you, and secondly, hi mom. And forgive me for repeating myself. I promise to change things up just enough, and hopefully this iteration makes more sense than the last ones, because hopefully my argument/reasoning is becoming clearer. And with that, let's get on with it.
Topics of Discussion, and Degrees of Complexity
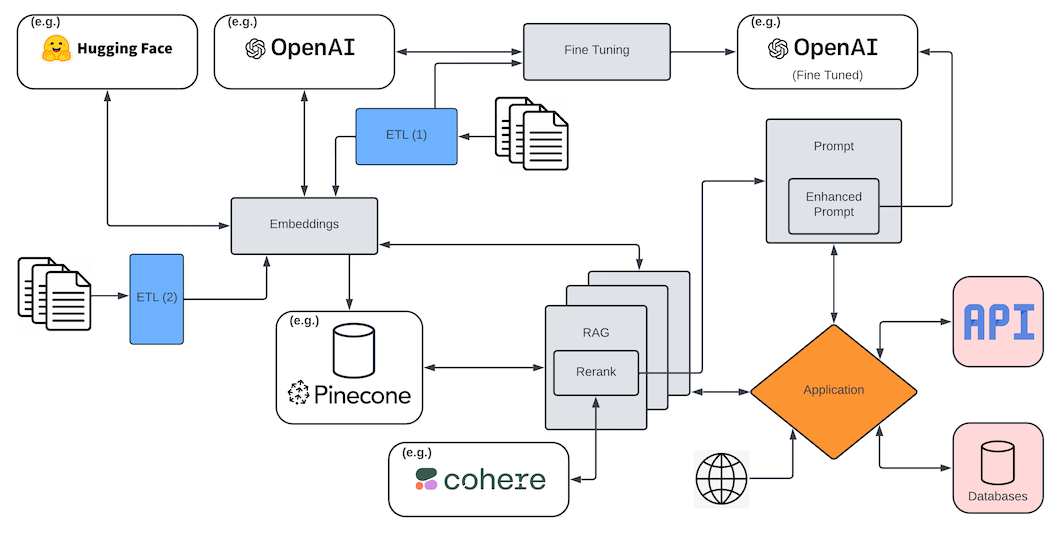
I'm going to start with this very back-of-the-envelope chart that attempts to illustrate the complexities of implementation, at a production and at-scale level, of the various components of the AI ecosystem that I'm going to cover within this post:
I'm not going to get into any of it here, beyond perhaps some disclosures. First, all things are relative. If there are any Prompt Engineers reading this, yes, there are complexities to what you do. And no, that's not a real job, so expand your skill sets and demand a less ridiculously stupid title. Also, I'm going to be using my own definitions. Surely there are far more rigorous definitions out there for some of these things, and I'm drawing my own boxes around what constitutes what, but, see earlier comment, I'm not getting paid for this shit, so I'll do it the way I want. I'll try and justify why I have some things yellow and other things red, and I'll probably have to do some revision on this before I publish it, which is to say that all of this is a little fuzzy to start with. Okay, that's bullshit. I'm not even going to proof read it, much less revise it, my (singular) reader be damned!
The LLM Itself
I'm going to spend very little time on this, because there is more than enough material out there on Large Language Models (LLMs), and because, well, you're not training one. I keep coming back to this, and I keep finding people in the wild who don't believe me. You and your company are not building an LLM unless you're the likes of (e.g.) Google, Microsoft/OpenAI, Bloomberg, or Apple. And more importantly, WHY WOULD YOU BUILD A LLM?!?!? This is quickly becoming (simultaneously) an overly saturated ecosystem and one that will ultimately have a handful of winners, and we're already seeing that. When we talk about LLMs, we're usually talking about the likes of GPT-4o or Gemini/Bard or Claude, or one of a small group of others. Honestly, I think this is a race to the bottom. From a cost perspective, only a small handful of companies have the means by which to build these, because the chips required and the cost of processing the neural network is prohibitive. And then, only those companies can get away with not charging inordinate amounts of money in a required attempt to recoup those costs. Instead, using the likes of gpt-4o continues to spiral downward, as evidenced by the image below, which shows that (at the time of this writing) you get a million input tokens for as low as $0.075 and a million output tokens for as low as $0.30. That's a significant difference from what it was a year ago, and there is no reason those prices won't continue to fall. It's a race to the bottom.

So, I am not going to waste a bunch of time on the complexities of building LLMs because it makes almost zero sense to do it. It's REALLY difficult to make a viable argument, for almost every company or organisation out there, as to why you'd build your own. I'm not talking about TUNING a model, I'm talking about TRAINING a model. It can make sense to tune one, but you're not training one from scratch.
That said, it's vital to our overall understanding and the rest of this post to be clear about a couple of things regarding LLMs. First, what they do.
A large language model (LLM) operates fundamentally by predicting the next word in a sequence, drawing on patterns learned from vast amounts of text data. Trained on diverse sources of language, these models analyze billions of word relationships, phrases, and sentence structures to understand context and meaning. Each word prediction is informed by statistical probabilities that allow the model to generate text that sounds coherent and contextually appropriate. Though this "next-word prediction" mechanism may seem simplistic, it enables LLMs to engage in complex tasks, from answering questions and composing essays to coding and creative writing, all by iteratively predicting one word at a time.
That is what a LLM does. It predicts the next word in a sentence.
That's really it, at the most basic level. It takes everything I've written up to this point, and predicts the next word should be...this. And that "skill" (if you will) stems from the massive data that went into training it. But let's keep it really simple in terms of how we talk about LLMs: they simply predict the next word. And do that over, and over, and over.
Fine-Tuning
Tuning a LLM is different. Tuning a LLM involves taking a copy of a foundational LLM (like Claude) and "adding specific data to it" (kind of) so that the predict-the-next-word algorithm is more fine tuned to your organisation or company. When you fine-tune an existing LLM, you’re not building a model from scratch but rather adapting a pre-trained model to perform better on specific tasks or respond to specialized data. This process involves adjusting a set of parameters within the model using task-specific examples or company-specific data, refining its responses to be more relevant or accurate in particular contexts. Fine-tuning is efficient because it builds on the model’s existing language understanding, allowing it to "learn" nuances, jargon, or desired behaviours without the extensive computational resources needed for training a new model from the ground up. This makes it a cost-effective and powerful way to create a tailored AI solution, leveraging the strengths of a foundational model while aligning it with your organization’s unique needs.
This approach has complexities and limitations. First, you copy the foundational LLM locally in order to tune it with your data. But the company building the foundational models (obviously) isn't taking your data into consideration. Rather, you've taken a model trained on data up to a certain point in time, and that's all the data it has. If the company that "owns" the LLM updates it with more data, or other advancements, your copy won't magically receive those benefits. Instead, you have to re-copy it down and re-tune it. It's more akin to forking, where what you have is a point in time version, but the master keeps changing, and your version gets left behind, lacking the advancements of the master.
That's a surmountable challenge, but one worth calling out for completeness. What is more challenging is that the data preparation for tuning is a lot more effort than you think. And it requires a lot more data. And you have to choose the right techniques to tune it. It's very much not just blindly throwing data at it and somehow it magically leverages that data effectively. The model’s responses will be shaped by the examples it "learns" from; this often involves extensive data cleaning, labeling, and formatting to ensure consistency and relevance. Additionally, the fine-tuning process must strike a balance between retaining the model’s foundational knowledge and specializing it for new tasks, which requires careful calibration. Techniques like few-shot or zero-shot learning (providing minimal examples), instruction tuning (guiding the model's behavior with specific instructions), and Parameter-Efficient Fine-Tuning (PEFT) methods (such as LoRA or adapters) are often employed to adjust only certain layers or parameters, conserving resources and retaining flexibility. Managing these complexities requires both technical expertise and iterative experimentation to achieve the desired performance without overfitting or unintended bias.
I said earlier that you're not training a LLM. To be honest with you, most folks aren't going to get the expected benefits from fine-tuning, either. And even more folks are going to abandon their fine-tuning once they realise that the juice isn't worth the squeeze, for (dare I say!) the majority of companies that want to leverage AI. Not sure if the majority is accurate (though I suspect it is), but I will say this: every organisation out there will be able to leverage AI in some practical ways to derive value, and there are many ways to do that without the complexities or (often human) costs of fine-tuning. In my earlier complexity chart I note it is middle of the road complexity, but being easy to find examples and tutorials doesn't mean it isn't time consuming and incredibly challenging to get right, or that the ongoing monitoring of it to assure you've not overfitted (etc.) isn't further detrimental to the goal. Again, most organisations, I suspect, will find that the juice isn't worth the squeeze on this one.

Again, not saying that a lot of organisations that leverage AI aren't going to get benefits from fine-tuning. Nor am I saying that fine-tuning doesn't work, or that it isn't a powerful approach. Nor am I saying that the action of tuning is somehow beyond the skills of most organisations. All I am saying is that there are other techniques for adding your data to your AI solutions that will prove to be easier than fine-tuning, for (what I suspect is) the majority of AI implementations and for most organisations, and further, that doing fine-tuning right is a lot more effort and human cost than you'd be led to believe.
Performance Efficient Fine-Tuning (PEFT)
I mentioned this topic earlier, but I want to return to it and differentiate this particular technique. It's important to call out Performance Efficient Fine-Tuning (PEFT), as an alternative to fine-tuning (or more accurately, a technique of fine-tuning). PEFT is a method used to adapt LLMs to specific tasks with minimal computational resources. Instead of fine-tuning all model parameters, PEFT selectively trains only a small subset of them, often using techniques like LoRA (Low-Rank Adaptation) or Adapter Layers, which add lightweight layers or make small adjustments to the model.
This doesn't change any of the points I have been trying to make with regard to fine tuning; if anything, it further proves the point that this concept is harder than you'd think. It's more time consuming. It's more fraught with complexities than the proverbial label warns.
All that said, fine-tuning is leveraging your own data in order to adjust the predict-the-next-word behaviour of the LLM. That's the point of it. To make your AI implementation have more (as I said before) nuances, jargon, or desired behaviours than the foundational (general) LLM.

Basic Parts of the AI
I'm going to shift now to AI for the masses. When we talk about AI, we're always talking about three parts, and we're often talking about more than that. But fundamentally, we have the LLM itself, the regular context that we send to the LLM (such as "You are a helpful Customer Support Agent...") which I'm calling the prompt (or prompt engineering), and the query itself, whether that be a user typing in a question, or systematic input. So, the user has a query, we pass that query, along with some prompt engineering metadata, to the LLM. The LLM then uses predict-the-next-word capabilities to generate a response.
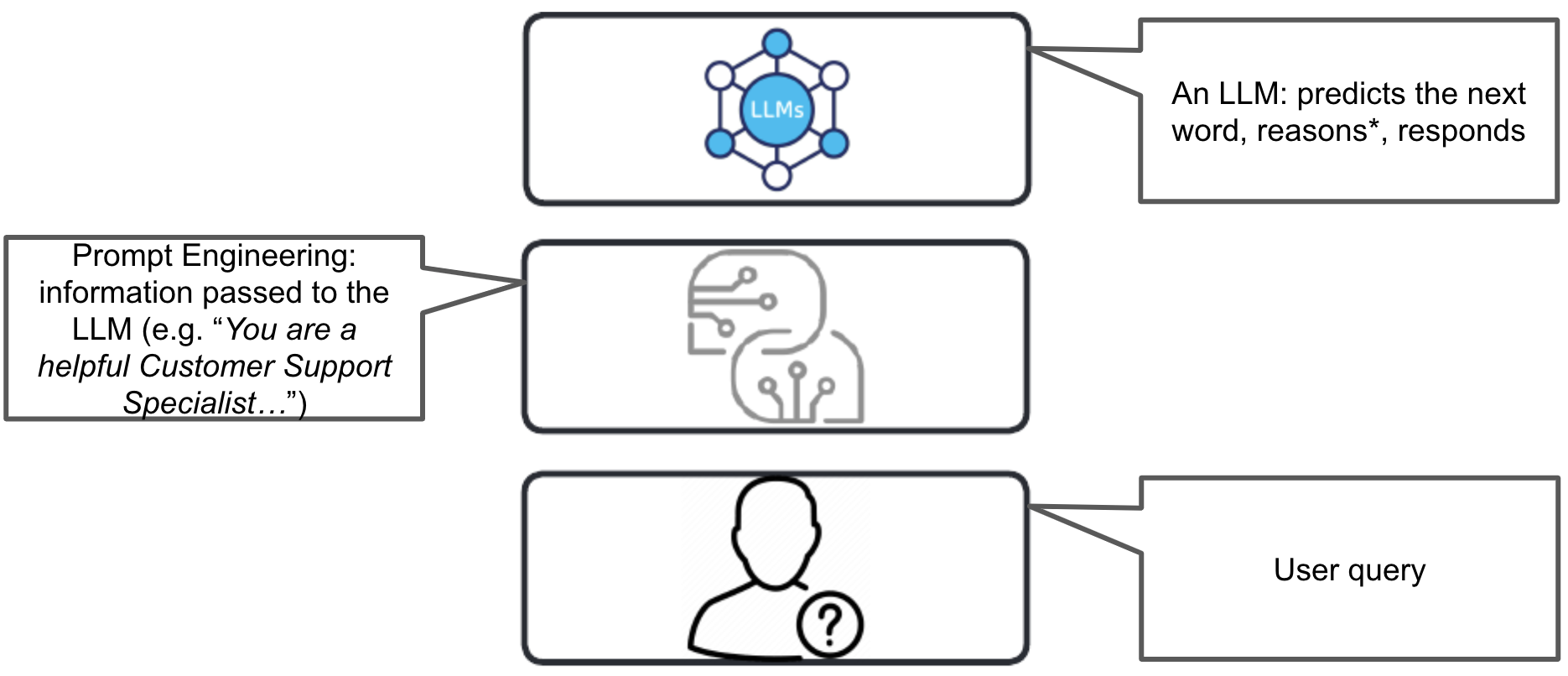
Now, when we interact with the likes of ChatGPT, we're using the capability of generating a response, AND we're using the knowledge that the underlying LLM was trained on. For instance, we enter a question like "Who was the greatest Minnesota Vikings quarterback of all time?" and it responds with a coherent answer, thanks to the predict-the-next-word capability, but it also has to answer the question, so it also has to retrieve some actual data from it's proverbial memory, if you will:
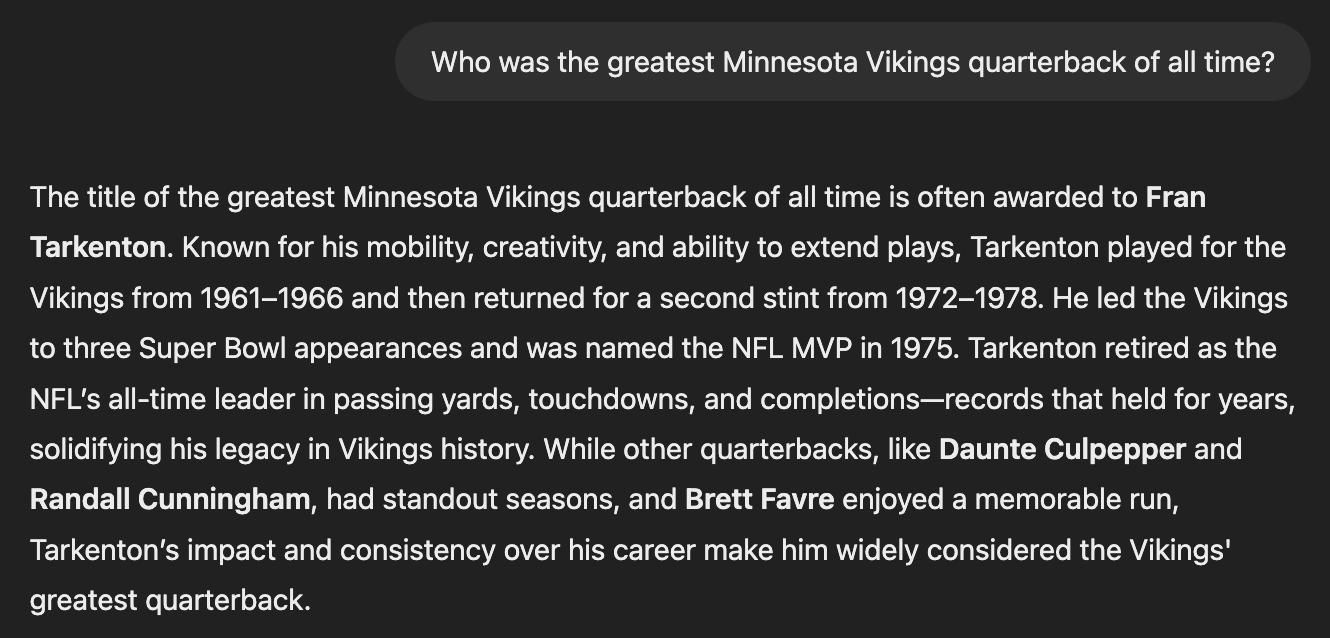
I mean, not even a mention of Tommy Kramer? If nothing else, this image deserves to live on, and hey Tommy, leave some ladies for the rest of us:

But I digress. The point I'm trying to make is the LLM is now doing two things: predict-the-next-word, and retrieve some data to answer the question. And this is where LLMs get into trouble, understandably.
Hallucinations
You have probably heard about hallucinations with AI, and I dare say, they're the biggest concern/complaint/reservation about leveraging these new technologies.
Hallucinations in LLMs occur when the model generates information or details that sound plausible but are factually incorrect or fabricated. This phenomenon stems from the model's reliance on patterns in training data rather than an understanding of factual accuracy, leading it to "fill in the blanks" with probable responses, even if they aren't true. Hallucinations can pose challenges in applications where accuracy is critical, such as in legal, medical, or educational fields, where misleading or false information can have real-world consequences. And even when the accuracy isn't potentially life threatening, it still causes harm, frustration, and a deterioration of trust.
Now we've talked a bit about the downsides of LLMs. In particular, they are trained on a massive corpus of information, but they don't necessarily have YOUR information. And we can help that with tuning, but that doesn't do enough, and it's far more complex than we appreciate by doing a simple Hello, World tutorial, to say nothing of the complexities and costs of testing that tuning and measuring the accuracy of it, avoiding over-fitting and generally walking the finest of lines. And we've talked about hallucinations, and the fact that LLMs in-and-of-themselves get shit wrong. And we've even touched on why that is: the LLM's real skill is in predicting the next word. That is what it is designed to do, and it does that really well. There have been plenty of times that ChatGPT has told me something incorrectly, but never has it spewed out a bunch of words that don't fit together. As I've said in the past, it's like talking to someone from the UK. Great sentences and word usage, but some of da shit they say just ain't right.

Agents
Here's where I'll start to skate on thin ice re: definitions. An AI "Agent" is an autonomous system designed to perceive its environment, make decisions, and take actions toward achieving specific goals, often adapting dynamically based on input and context. I think that aspect of the definition is largely settled. Where it gets fuzzier, in terms of how I think about "Basic" Agents is that I have a lower bar for what "agency" they need to have. Allow me to try and explain, and again, with a bit of leeway here. I'm more concerned about conveying the idea than getting into some pissing contest about the term I'm using, but...
Back when I was a young strapping buck, in late 2022/early 2023, I was lucky enough to meet someone who was looking to "replace her job with technology." This was around the time that the AI wave was beginning to form. I am sworn to secrecy (via NDA) on the details, but I can reveal that the solution was very rooted in generative AI, and specifically leveraged the basic components of AI, as described earlier. So, without revealing what her job was, it was the combination of building blocks (LLM, prompt engineering, query) that was used to do so, with two important additions: history and a UI. Essentially, this took those building blocks and allowed the user a means (the UI) by which to interact with the system, and further included infrastructure and architecture that allowed the prompt engineering to be enhanced further with previous conversation, as additional input. Nothing all that special here, and there's more to come, but worth pausing here to make sure we're shining a light on these additional components, because while they are not complex, they are important!
This history gives the AI context for the rest of the conversation, which I cannot overstate the importance of enough; vitally, the AI has no "real" concept of the conversation it has had with you. Instead, with each user input with the AI, the rest of the conversation is passed in, thereby providing that history with each independent interaction. I think of it this way: like the Adam Sandler and Drew Barrymore movie, 50 First Dates, where Barrymore has short-term memory loss, and each day when she wakes up, Sandler has to start all over again, and of course as time goes on, the amount of history he has to explain to her gets longer and longer. Older memories have to be summarised, and more recent memories that are more applicable to the current interaction have to be built upon. This is exactly the same as AI works as history is passed via the prompt.

Worth noting: this management of history is not easy, even if it is simple. Essentially, you're managing order, since out of order questions and responses ruin any chance of the AI being able to effectively leverage that data to respond accordingly. Also, as that history grows, you can quickly run out of tokens (think of it - roughly - as allowed number of words) that you can pass into the prompt, thus, you're forced to do things to that history to compress it, such as summarising older interactions. And you have to externally persist it (at scale), and you have to make it accessible to the system in a performant manner, since you can't afford to lose time to things like database querying when you're already at the mercy of the time it takes the AI to predict-the-next-word. It's pretty straightforward to do in the Hello, World tutorials, where your persistence layer is the application code itself and the history is generally limited. But don't discount it as "easy", because at scale in production systems, it quite simply isn't. Every layer of the AI requires real consideration, and this is a foundational aspect of whatever it is you're going to build, so getting this wrong will surely undermine everything else you're going to do on top of it, and there is still A LOT to be done for us to move from poetry to prose!
While I'm going to hand-wave a bit over the UI/API, there is something there worth calling out, even if it is otherwise implied. The API and/or UI are essential components that make AI accessible and usable, acting as the bridge between complex model operations and end-users or developers. The API allows seamless integration with other applications, enabling developers to incorporate AI functionality into existing workflows or systems with ease, while the UI offers a more user-friendly, visual interface for interacting with the AI directly. Together, they transform the underlying AI capabilities into practical tools that can be leveraged by non-technical users and professionals alike, expanding the reach and utility of AI in real-world applications.
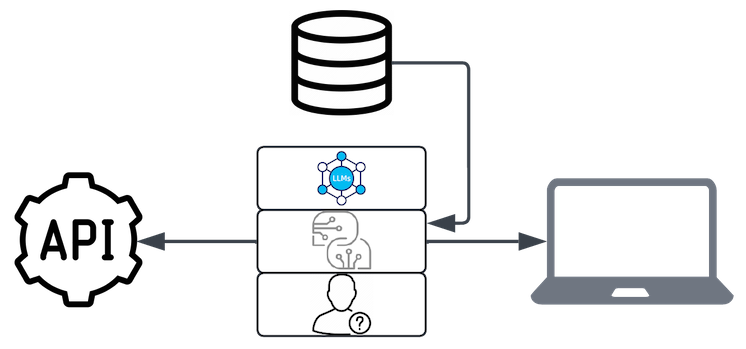
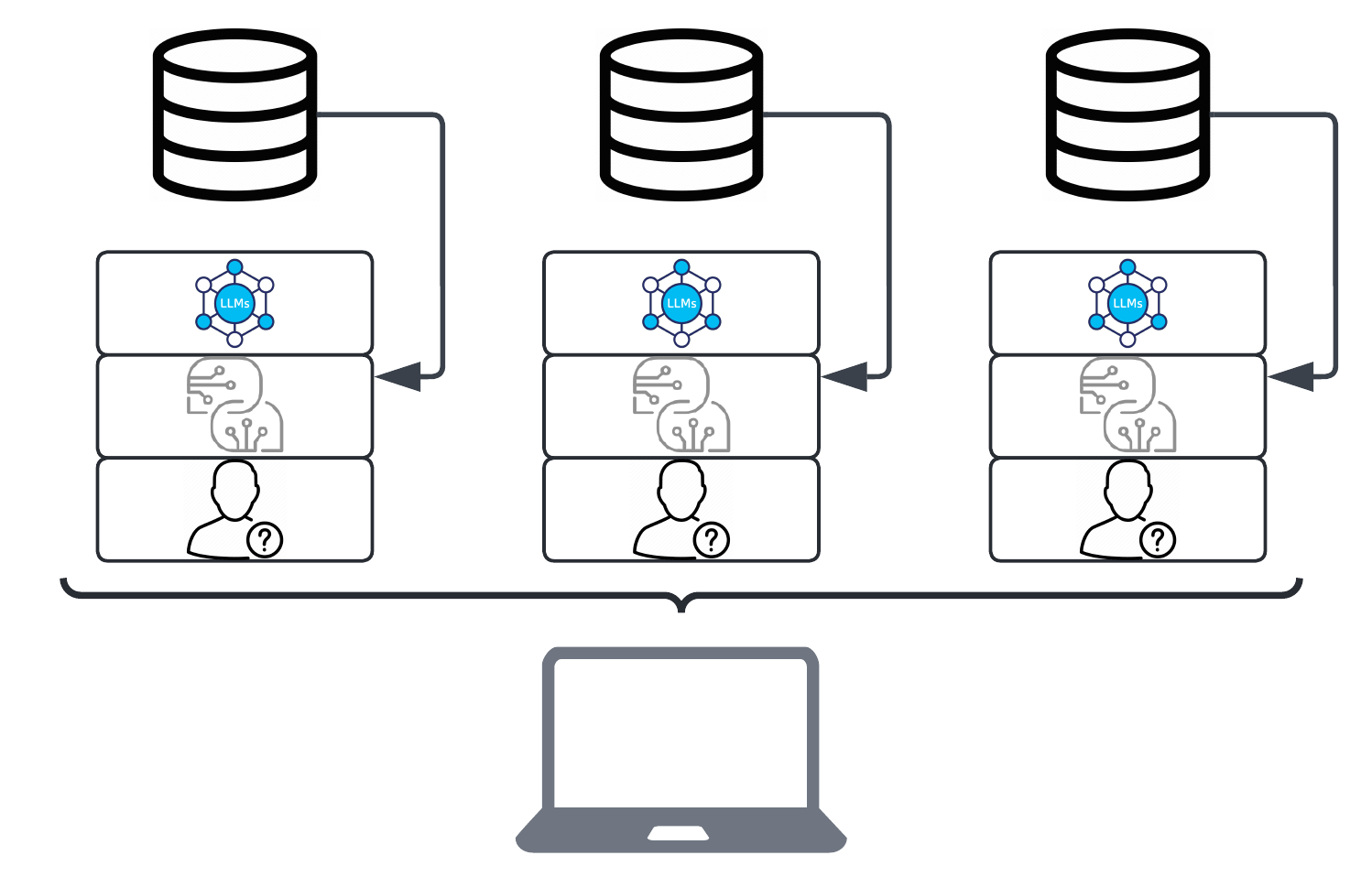
Okay, so just to recap so we're both on the same page: now we have these basic components of AI (LLM, Prompt, User Query), and we've extended that Prompt to include history, externally persisted, and we've built one or more ways for users to interact with the outside system, via API and/or UI. Sticking with the previous professional experience of "replacing her job with technology", the secret sauce that I recommended was to take all of this and replicate it three times, so that I could create three independent threads for the user to interact with. Again, since I am bound by NDA and a sense of general professionalism, I won't divulge the details, but I can use a different example to aid in the explanation. Let's imagine, if you will, that the solution was to create a means by which to foretell the future. We can imagine that this individual was some sort of Mystic. My idea was to create three independent mystics, and allow the user to have separate relationships with each one. Further, each mystic would be given the same starting information about the user, but from that point on, their relationships would be independent. Imagine, if you will, that we handed the tarot card reader, the astrologer and the crystal healer the same (base) bio of the client, but any conversation between client and mystic would be separate from that point forward.

I (admittedly loosely) think of these independent AIs, each with their own prompts (one is "you are a tarot card reader...", another is "you are an astrologer...", and so on), and each with access to their own historical conversations with each independent AI, as "Agents." This allows the user to develop independent relationships with each of the AIs, which can lead to very different outcomes. With each interaction with each Agent, we proverbially tweak the direction of each ship some number of degrees; over time, the destination where each ship may head towards can be further from the others, and there is a lot of power in this independence.
Where I might get some reader cringe is that the "agency" that any of these particular AI's have is debatable, but again, it's my post and the important thing is understanding of the concepts here.
This is All Just Poetry
The thing that needs to be realised here is that all of this, while (hopefully!) interesting, is not enough to shift us from poetry to prose. Yes, there are some interesting things we can do with independent AIs, like I've described above. In fact, developers, product folks, and users alike might find interesting aspects of building, productising, and even using systems that are comprised of these basic components. But the hard truth is that it is very, very few and far between where this is actually enough to create a practical, or even surface level, compelling solution, hard as that may be for organisations to accept. It's enough to create a novel toy, but that's just the sizzle and not the steak. And I think this is a big part of the first AI wave that has since washed over us: it was this massive promise of AI, that it could do all these amazing things and was going to replace all the jobs and write all the books and create all the movies and cure all the diseases and predict all the futures, because it could actually dynamically respond to us in a really (seemingly) intelligent way, drawing on so much more information than we as humans could ever learn or remember. But in real life, it was just predicting the next word and in the process creating sentences, but just handing an AI some history or additional information was only really enough to create some interesting apps; but that alone doesn't change the world.
Retrieval Augmented Generation (RAG)
At this point, most folks know about RAG, and I've talked extensively about it in earlier posts, so I'm not going to spend a ton of time on it here. RAG is a powerful approach in AI and natural language processing that combines retrieval and generation techniques to create more accurate and contextually relevant answers. In RAG, a model first retrieves information from a database or knowledge source, like a set of documents or a knowledge base, based on the input query. Then, it uses this retrieved information as the knowledge base to generate a response, enhancing its answers with relevant facts instead of relying solely on pre-learned data.
To visualise this, I'm going to extend the basic building blocks of AI that I've been using up to this point, and add a second source of data to it (the first being history). Now, when a query comes in from a user, not only do we retrieve the previous conversation to pass in the prompt, but we also do some magic to retrieve additional information that is also passed to the prompt.
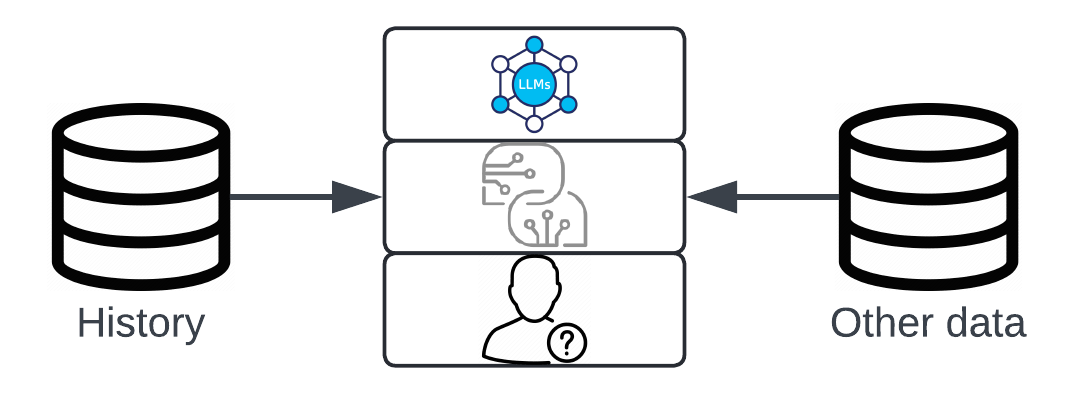
This approach is especially useful in applications like question answering and chatbots, as it allows the model to access fresh, detailed, and specific information, leading to responses that are both informed and highly context-specific.
Often, the source of the additional data is from vector databases, which have enjoyed a new lease on life with the explosion of AI. In these systems, documents are chunked into parts, then converted from text to a series of of coordinates, like you'd have in a normal two dimensional graph, except that this has hundreds or thousands of dimensions. This is especially useful in AI scenarios because of semantic searching.
Semantic searching is enabled using vector databases by transforming words, sentences, or documents into high-dimensional vectors that capture their meanings, rather than just their literal terms. Vector databases then store these vectors and allow for fast, efficient similarity searches based on the relationships between vector representations. When a query is made, it’s converted into a vector, and the database finds items with vectors that are "close" to it (either via cosine or euclidean or dot distances), reflecting similar meanings or contexts. This approach enables semantic searching because it retrieves information based on conceptual similarities rather than exact keyword matches, which is especially useful for natural language processing tasks where nuanced understanding is needed. Vector databases are optimized for these types of searches, making them ideal for applications like recommendation engines, question answering, and conversational AI.
One additional note on vector databases that I'll call out is that an index within a vector database is not a single catch-all dumping ground for all your shit. Instead, thought and consideration needs to be added to how those indices will be organised. Using separate vector database indexes is often preferable to a single index because it allows for more targeted and efficient retrieval, reduces noise, and enhances accuracy. With multiple indexes, each can be optimized and structured around specific domains, content types, or query contexts, making it easier to manage and scale as data grows. Separate indexes allow for faster query times, as the system can bypass unrelated data and focus only on the relevant index, which is especially beneficial in high-volume or diverse datasets. Additionally, it provides better control over relevance tuning and embedding dimensions, enabling you to fine-tune performance for distinct use cases without interference from unrelated data, ultimately leading to more precise and reliable results in applications like personalized search, recommendation systems, and retrieval-augmented generation.
To be clear, these new external data sources needn't be vector databases, but because they are so common (because of the semantic search capabilities that benefit unstructured and dynamic user inputs), they deserve the extra call out that I've given. But more holistically, those external data sources could be relational databases, graph databases, file systems, etc. The thing to walk away with here is that it's some additional data that will be "intelligently" retrieved based on the query, and passed via the prompt to the LLM, thus hitting each layer of the basic building blocks. So again, I could open myself up to debate by calling these things "Agents" because the basic building blocks don't necessarily have "agency", but I'm going to stick with it because they do have some level of decision making in terms of what they're querying and how they're using that retrieved information to formulate a response.
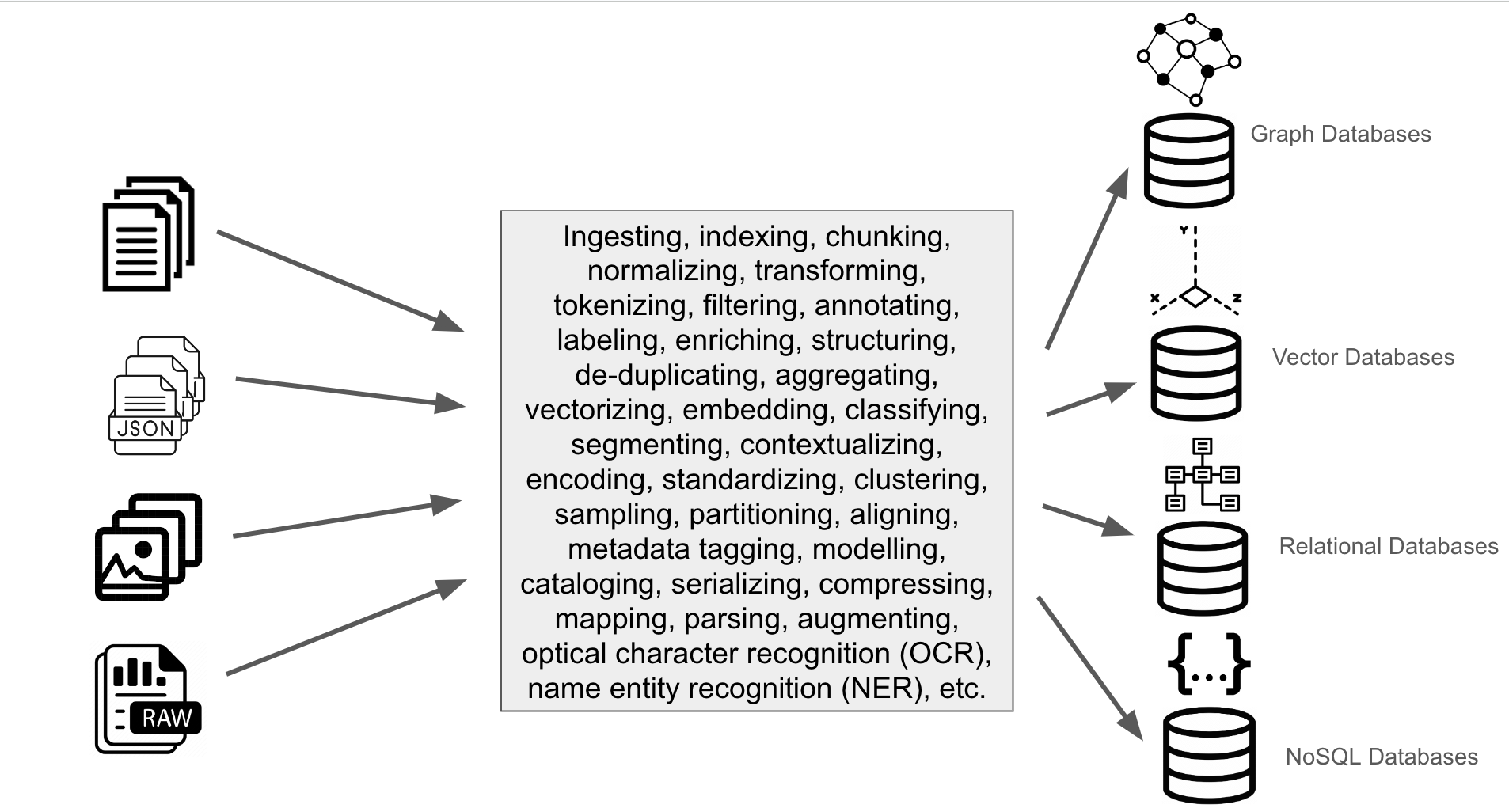
Vitally, the preparation of the data in-and-of-itself is a significant undertaking. Beyond the chunking and tokenising, there is labeling, enriching, structuring, tagging, and a host of other things that have to be done. And that doesn't even begin to talk through the more advanced (and deserving posts to themselves!) of things like optical character recognition (OCR) and name entity recognition (NER), etc. Again, the Hello, World tutorials give us an idea of what has to happen, but they (almost irresponsibly) hand-wave over the complexities of this, especially at scale! I talk to folks regularly who absolutely understand the concepts of RAG, but see it as a singular pipeline, whereas the reality is very much the opposite of that: in mature AI shops, I expect to see hundreds, and perhaps even thousands of independent RAG pipelines and access patterns into disparate external data sources. Each of those pipelines has to be optimised, their data transformed and validated and prepared, their results monitored, their systems observed, and so on. Much of AI is not understood enough to be appreciated for the complexities that accompany it. Quite possibly none more than RAG.
Agency
I'm building towards the shift from poetry to prose, and a big component of that is this concept of giving an AI agency. And because the next step of this conversation is AI Workflows, I think it's best to define agency, so that we can differentiate AI Workflows that lack agency, and Agentic Workflows that have agency.
Agency is the capacity of an entity—like an AI Agent or person—to make independent decisions, act based on available information, and adapt behavior in response to changing conditions. Unlike following fixed rules, an Agent with agency can evaluate situations, set goals, and choose actions that align with its objectives, even in unexpected scenarios. This autonomy allows it to operate with flexibility and purpose, making it responsive and capable of driving outcomes rather than passively executing predefined steps.
AI Workflows
AI workflows, without agency, are highly structured systems where tasks are carried out in a fixed, predefined order, typically through a series of sequential or conditional steps. Each task is completed based on established rules and triggers, dictating what happens next, without any autonomous decision-making. In these workflows, each step waits for the previous one to finish or for a specific condition to be met before proceeding, following a predictable path. The absence of agency means that the system lacks the ability to adapt or make decisions beyond its programmed instructions, making it effective for repetitive, predictable tasks but less suited to complex or evolving scenarios.
Without agency, these workflows cannot independently respond to unexpected changes or new information. If a task encounters an unanticipated problem or deviation from the norm, the workflow may fail or require manual intervention, as it cannot alter its path or determine an alternative approach. This rigidity contrasts with Agentic workflows, where at least one Agent has the autonomy to assess situations and adjust actions accordingly. Non-Agentic workflows are best suited to routine processes, where reliability, consistency, and strict adherence to predetermined steps are essential, rather than flexibility or adaptive intelligence.
AI Workflows, then, are essentially a series of basic Agents who are accessed via a directed acyclic graph (DAG). They're akin to a basic decision tree. Do this, then do this, then do this. Perhaps within that flow, there are some if/thens that determine what will happen next. This is the first step towards practicality, and it's a huge step. Especially if we truly appreciate all of the complexities that have come before it!
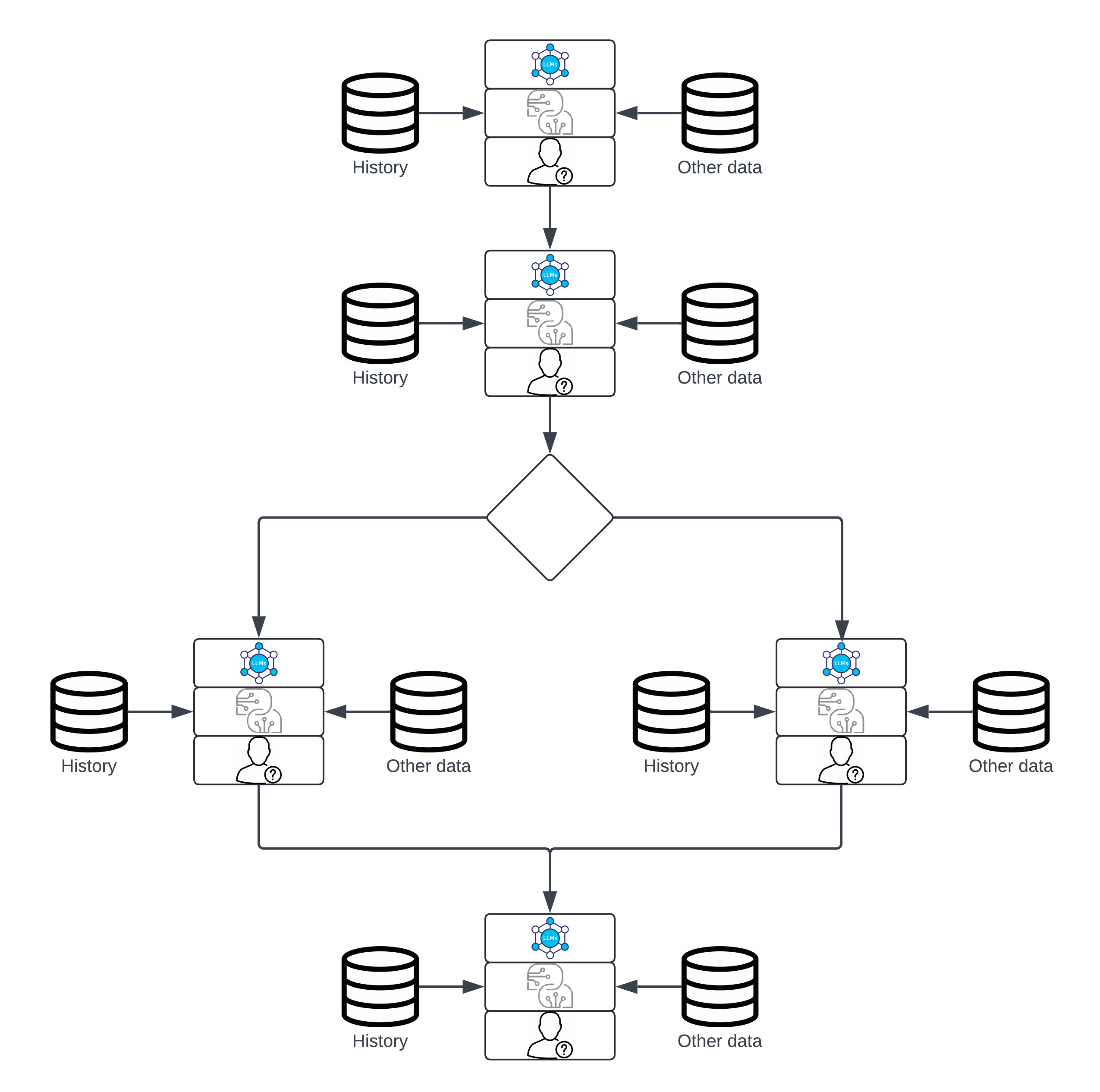
What is interesting/exciting here is that the various external data sources could be all kinds of things. Some may be accessing different indices in vector databases, others could be accessing relational databases, etc. Each of the independent Agents have access to their own "knowledge bases" (if you will). This combination of isolated and targeted data sources, coupled with the various steps that problem solving almost inevitably entails, leads to us being on the brink of something really powerful, and on the brink of shifting from poetry to prose!
This is a Lonely Place

Probably the other thing that is really interesting here is that very few organisations have reached this level. Why? Because this shit is harder than you think. In fact, I think we're still trying hard to figure out where the hell AI even fits organisationally within your company. It kind of feels like it belongs to the Data and Analytics department, since that group usually includes Data Scientists, and Data Scientists have overlap to the technologies that AI uses, particularly neural networks. But, like we've seen in this post (and many others), you aren't actually creating the LLM or using a neural network in that way. In fact, I could strongly argue that the AI group belongs far more to the Data Engineering side of Data and Analytics than it does Data Science, since the reality is that much of the puzzle is in about assembling the pieces the right way. There's nothing about Prompt Engineering that is (capital "D", representing the team) Data. There's nothing about building out a production-grade persistent storage layer for history that is Data. There's nothing about building out RAG pipelines that is inherently Data. Rather, it's this gut feel that AI belongs to Data, even though the skills of Data (SQL, analytics, machine learning) don't actually have too much overlap to the pickaxe and shovel efforts, or the deep architectural understanding of the technologies themselves that are fundamentally required to build out effective, practical AI ecosystems.
And while I do want to write about this at some point in the future, I don't have a lot of practical experience to back up my theory/belief, but my belief is that AI departments should be completely independent to other technology groups within your organisation. It is true that a deep understanding of data and analytics and machine learning is helpful, but...those understandings are helpful in creating every solution. Rather, I believe that those understandings are essentially as (and no more) important as an understanding of DevOps, and application development, and cloud architecture. Find me a software engineer with deep cloud experience and deep, deep architectural understanding, and data and analytics (including Data Science), and you've found the right persona to build an independent team around for your independent AI department.
Prose: Agentic Workflows
Agentic workflows refer to systems in which tasks are completed through the interaction of autonomous Agents, each responsible for specific tasks or goals within a process. In such workflows, at least one Agent must have agency—meaning it can make independent decisions, act on information, and adjust its behavior based on changing conditions or outcomes. This agency is what allows the workflow to operate dynamically, as the Agent with agency isn’t just following rigid instructions but can respond adaptively to achieve the desired outcome. By leveraging Agents with agency, these workflows become more flexible and resilient, especially in complex or unpredictable environments, as Agents are empowered to drive tasks forward intelligently rather than just passively executing predefined steps.
Again, at least one of the Agents within an Agentic Workflow must have true "agency", which I realise I've already defined, but I'll do so (slightly differently) again, to really reinforce it.
Agency refers to an entity's ability to make purposeful decisions and take actions autonomously to achieve specific goals. Rather than merely executing predefined instructions, an Agent with agency assesses its environment, interprets relevant data, and chooses from various possible actions based on its objectives. This decision-making ability enables it to handle complexity, adapt to changes, and navigate situations that may not have been anticipated in advance. Through this dynamic capacity, agency empowers an entity to contribute actively toward desired outcomes rather than functioning as a passive tool.
In this model, we have at least one Agent that we're handing a query to without a direction as to how to make the decision as to how to answer it. Instead, we give this Agent (with Agency) a set of different resources (other Agents, with or without agency) and independent external data sources (knowledge hubs) that they can retrieve information from. In this model, the user query that these "other Agents" get as input is the output from the Agent with agency. Even typing these words, the complexity (and risks!) of this model become apparent. And unfortunately, it's not this simple. This all gets to the discussion of Multi-Modal Generative AI, and the definitive paper on the topic, Multi-Modal Generative AI: Multi-modal LLM, Diffusion and Beyond.
In multi-modal Agentic workflows, specialized Agents process distinct data types independently—such as a language model interpreting text, a vision model processing images, or a diffusion model generating visuals—before coordinating and integrating their outputs into a coherent response or action. This setup empowers Agents to collaboratively produce more sophisticated outcomes, where insights from one modality inform or refine actions in another. By supporting Agents that can seamlessly transition between or combine multiple modes, multi-modal Agentic workflows enable more complex, adaptive responses to tasks that involve diverse forms of information, making them highly effective for scenarios like content creation, cross-media analysis, and interactive user engagement.
Multi-model Agentic workflows involve the coordinated use of multiple specialized models or Agents, each optimized for different tasks or types of data (e.g., language processing, image recognition, data analysis), working collaboratively to achieve complex goals. By leveraging each model's unique strengths, these workflows can handle diverse input formats and perform a broader range of actions, allowing for a more robust, adaptable, and contextually intelligent response to complex tasks. This integration supports seamless information flow and decision-making across models, enhancing the system’s overall capability and flexibility.
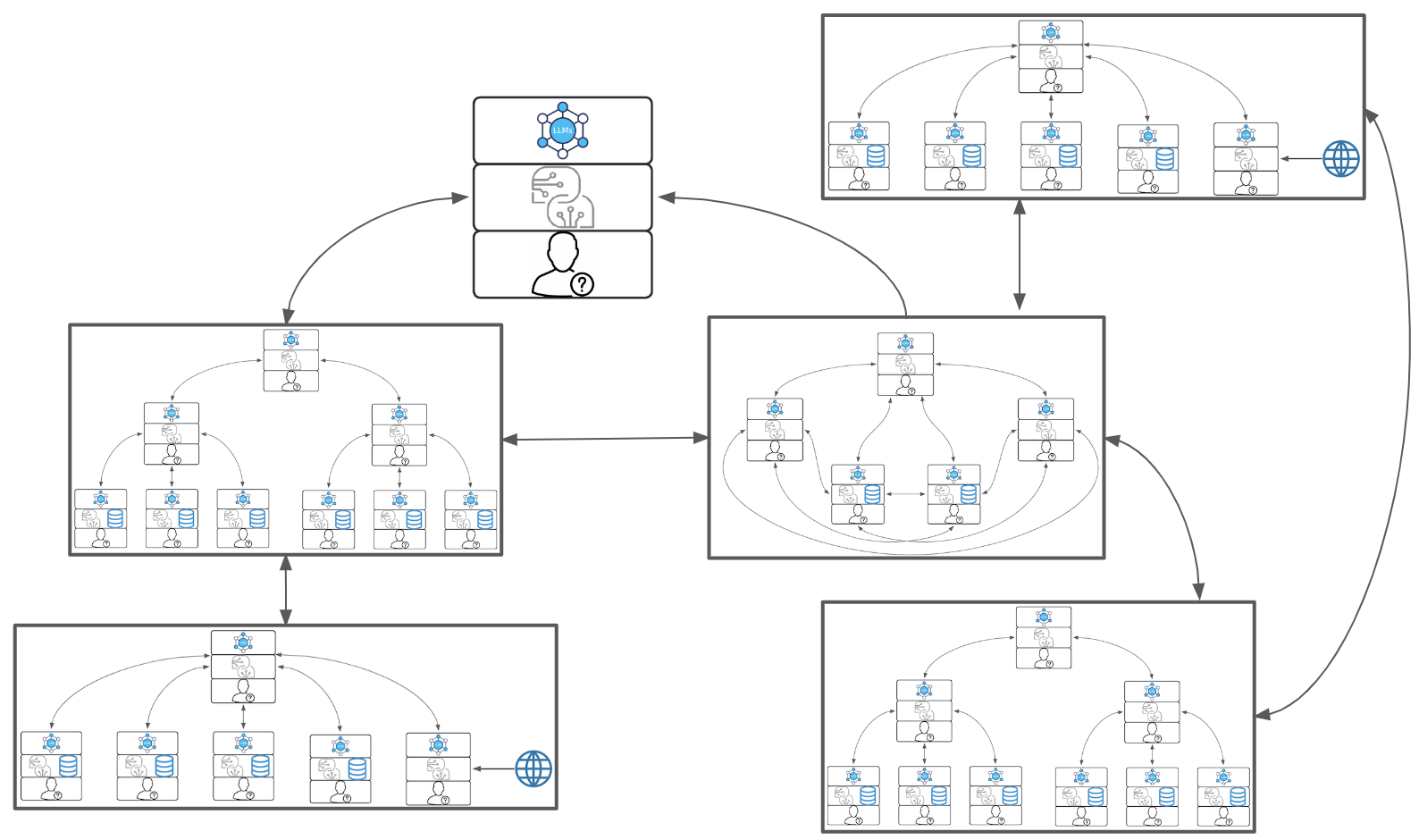
There are a number of different patterns of Agentic workflows, and I'll quickly cover a few of them here.
Supervisor Agentic Workflows
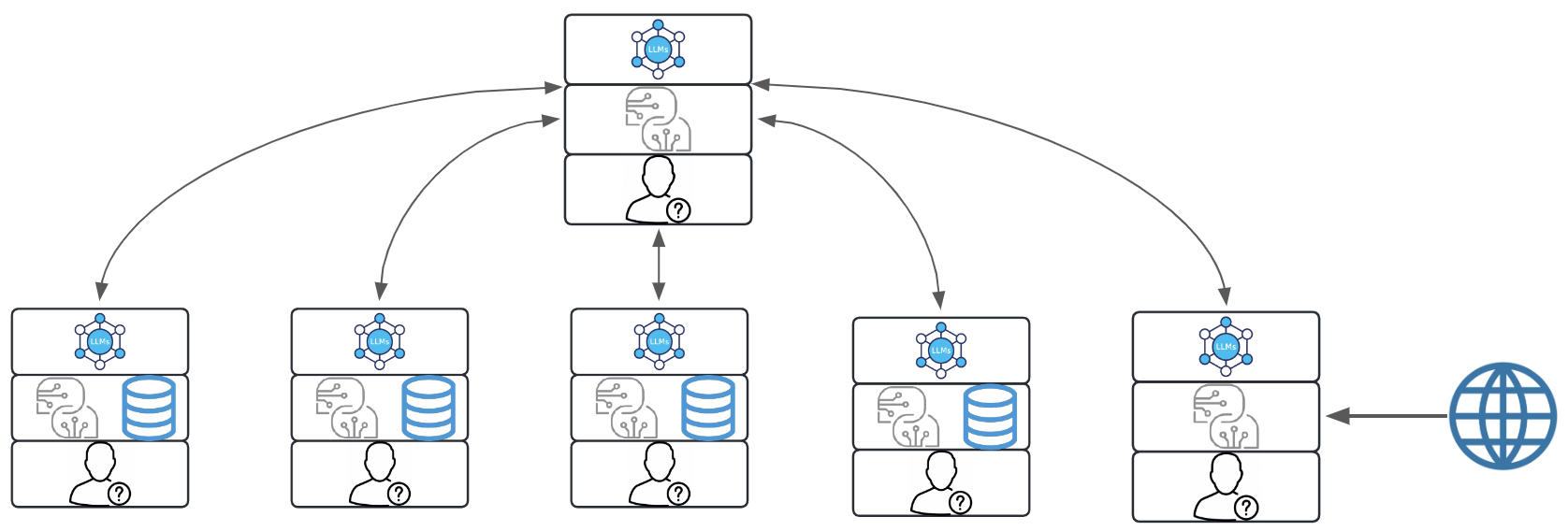
Supervisor Agentic Workflows involve a central supervising Agent that delegates tasks to other Agents, oversees their progress, and consolidates results. This model is useful when one Agent possesses higher-level control and decision-making responsibilities, allowing it to assign subtasks according to the capabilities and specializations of subordinate Agents. The supervising Agent checks in on each step to ensure alignment with the overall goals and can provide corrections or optimizations as needed.
Hierarchical Agentic Workflows
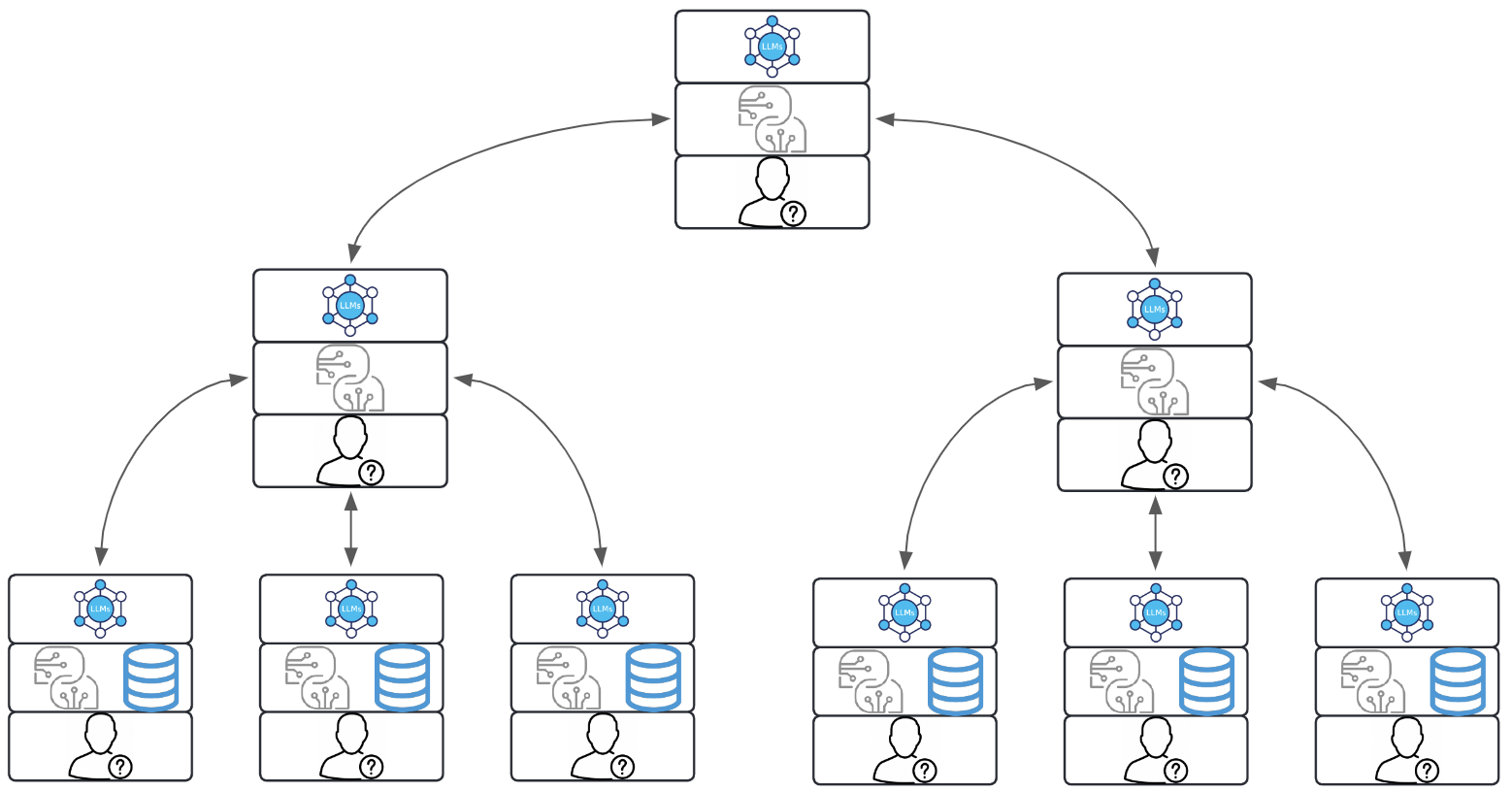
With higher complexities (and in many cases, bigger upside), Hierarchical Agentic Workflows structure tasks in multiple levels, where Agents work in a tiered manner, often with each layer passing completed work to the next. In this setup, Agents at each level have distinct responsibilities based on their position in the hierarchy, making it easier to break down complex tasks and channel them through sequential stages. This approach is particularly effective for projects that require stages of review, approval, or refinement at different levels before the final output is achieved.
Collaborative Agentic Workflows
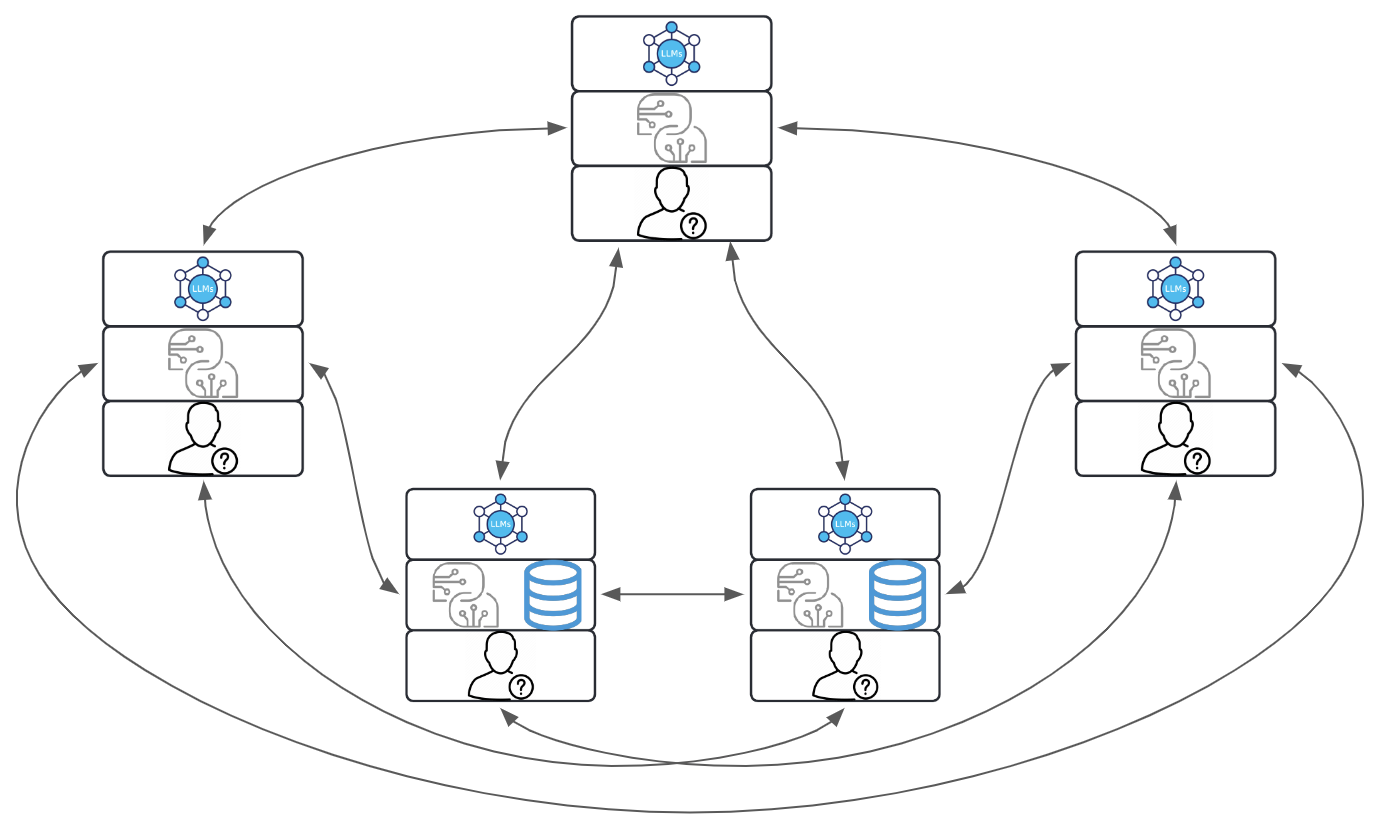
With even higher complexities (and in many cases, even bigger upsides), Collaborative Agentic Workflows focus on peer-to-peer cooperation among Agents, where each Agent contributes independently yet actively shares information, resources, and updates with others. This decentralized structure supports flexibility and innovation, as Agents can build on each other’s work in real-time or asynchronously, combining strengths and insights. Collaborative workflows suit tasks that benefit from shared knowledge, diverse perspectives, or continuous adaptation to dynamic requirements.
Complex Agentic Workflows
I'm not going to spend a lot of time on this, because (a) it's relatively straightforward conceptually (the combination of the types of Agentic workflows that I've described previously), and (b) because it's a North Star, and significantly more complex. We must crawl before we walk, and walk before we run. This is more like flying a jet.
Complex agentic workflows can integrate multiple types of agentic workflow structures—such as hierarchical, collaborative, and supervisor models—within a single, dynamic framework, amplifying both their power and sophistication. In such systems, a supervisor agent might oversee the entire process, delegating tasks down a hierarchy of specialized agents while monitoring progress and providing corrections as necessary. Meanwhile, within this hierarchy, collaborative agents at various levels can share insights, cross-check results, or improve outputs based on real-time data exchange and feedback, leveraging each other’s strengths for innovative problem-solving. The result is an intricate, highly adaptive ecosystem where agents continuously coordinate and adjust actions to meet complex objectives, capable of achieving outcomes that no single workflow model could handle alone.
This multi-layered approach enhances the flexibility and robustness of the system, allowing it to tackle intricate tasks that require both sequential processing and peer-to-peer cooperation, such as multi-modal content creation or advanced decision-making scenarios. However, with the added complexity comes the excitement of higher-stakes outputs, as combining different agentic workflows opens the door to more nuanced, contextually intelligent results that are precisely adapted to evolving inputs. The collaborative insights within hierarchical structures and the high-level guidance from supervisor agents create a combination that can lead to powerful, transformative outcomes, pushing the boundaries of what AI-driven workflows can achieve.
Wrap it Up!
The evolution of AI from "poetry to prose" requires a shift beyond the foundational building blocks of LLMs, simple prompts, and basic AI workflows. As AI technologies and frameworks mature, we are now positioned to leverage more sophisticated and dynamic models, allowing for greater adaptability and functionality within Agentic workflows. These workflows, empowered by Agents with genuine autonomy, bring the promise of AI closer to meaningful, real-world applications, moving beyond speculative benefits toward tangible, practical outcomes for businesses and organizations. By understanding and deploying Agents with true agency, we unlock capabilities that enable AI systems to respond intelligently and flexibly to complex, real-time demands.
Integrating Retrieval-Augmented Generation (RAG) and fine-tuning into Agentic workflows significantly enhances the ability of AI systems to deliver relevant, customized responses by leveraging both external and specialized data. It is through this technique that we minimise (and ideally, eliminate) hallucinations by replacing the data that the AI uses in response with an isolated and manicured knowledge base. RAG allows Agents to retrieve real-time, context-specific information from various knowledge bases, reducing the reliance on the static, pre-trained knowledge within an LLM. By dynamically pulling in updated or specialised data, RAG enhances the accuracy and relevance of responses, especially for complex, evolving domains. Meanwhile, fine-tuning takes this a step further by tailoring the foundational model to an organization's unique language and requirements, helping Agents better align with specific tasks and contexts, but is often not truly applicable for your organisation, because the outcome is not proportional to the cost or time. In any case, RAG and/or fine-tuning can create a powerful synergy within Agentic workflows (cannot believe I am using the word "synergy", which generally makes me vomit in my mouth, but it works here), balancing broad language understanding with precise, domain-specific knowledge to enable Agents that can make more informed decisions and deliver increasingly refined outputs across a wide range of applications.
AI workflows without agency are a step towards prose, and serve a critical function in handling routine, well-defined tasks through a structured sequence of steps that follow predefined rules and conditions. These workflows excel in predictable environments, where tasks can be executed reliably without needing real-time adjustments or independent decision-making. However, their rigid structure can become a limitation in dynamic, complex scenarios where adaptability is required. Without the capacity for autonomous adjustments, these workflows depend on external intervention when encountering unexpected changes or nuanced demands. As a result, while non-Agentic AI workflows are powerful for specific, repetitive functions, they fall short in environments that demand flexibility and responsive, adaptive intelligence.
The variety within Agentic Workflows (where one or more Agents have agency), include Supervisor to Hierarchical and Collaborative models, and highlight the flexibility and power of these systems to manage different types of tasks and environments. Each model brings unique strengths suited to particular applications: Supervisor workflows offer oversight and control, Hierarchical structures manage staged processes, and Collaborative workflows foster innovation through peer-to-peer exchanges. This diversity allows organizations to tailor AI workflows to their specific needs, scaling from straightforward task management to intricate, multi-Agent collaborations that can evolve dynamically.
With the introduction of multi-modal and multi-model workflows, we extend the boundaries of what Agentic systems can achieve. By integrating Agents that specialise in different modalities—text, visuals, audio, and more—AI solutions can create richer, cross-modal outputs and interactions. Multi-modal Agentic workflows stand as a critical step toward intelligent systems that can handle the full complexity of human communication, diverse media types, and nuanced information processing. This progression not only amplifies AI’s applicability across industries but also represents a new frontier in the creation of adaptive, context-aware systems.
We're developing the patterns and practices to create layers upon layers of new functionalities and capabilities. Ultimately, if we believe Agents are a significant aspect of the shift from poetry to prose, then the North Star is complex Agentic workflows, combining the strengths of various agentic workflow patterns to ultimately create "intelligence" to do interesting things leveraging generative AI.
As we advance, the true potential of Agentic workflows lies in their ability to reshape how we approach problem-solving in AI, focusing on intelligent, resilient systems capable of independent decision-making. This next phase of AI development challenges us to refine and innovate continually, ensuring that our AI systems not only reflect the complexities of real-world tasks but also enhance the capabilities of the teams and organizations that rely on them. Ultimately, Agentic workflows are foundational to bridging the gap between AI's theoretical potential and its practical, transformative impact on our daily lives and industries.
As always, my sincere thanks for taking the time to read this nonsense! Peace.