 Joel
JoelDisclosure: All opinions expressed in this article are my own, and represent no one but myself and not those of my current or any previous employers.
As I've said a number of times over the years on this site, I enjoy writing and I find it therapeutic, which is me doing something selfishly, and I get the benefits from writing even if nobody reads it, in the same way that millions of people get positive effects from writing in a diary or journal.
I'm not sure if I'll post this one. Just throwing it out there. Usually, I go into these things pretty confident that I'll publish it to this site for anyone to see, and occasionally (perhaps a bit more frequently than that), I end up deleting whatever nonsense I've spewed. Sometimes, it's because it's garbage. Actually, it's always garbage, but on the garbage scale, sometimes it tips.

Sometimes, it gets too personal, and it makes me just a bit too uncomfortable. Other times, the feeling of Imposter's Syndrome is too strong, and I haven't earned the career capital or depth of understanding to deserve to post my opinions. I think this one is that. I feel like the past 20 months or so have been filled with learnings, specifically in the space of generative AI, and I feel like the foundation I had coming into it (decades of experience in software engineering, solution architecture, data and data science) meant I'd "get it" faster, because nothing is necessarily new, per se, but more realistically is now all accessible, thanks to the advancements of computational chips.
On the other hand, my answer for people new to their careers who want to advance, or advance faster than they feel they are: work more.
Yes, I know how that statement lands, because I've been saying it for years, though lately that type of honest assessment/opinion is enough to face massive backlash. Despite the mention here, I am not going to talk about cancel culture, because that isn't what I'm fighting against. In fact, I get why folks are pissed off. They should be.
The world's eight richest individuals have as much wealth as the 3.6 billion people who make up the poorest half of the world. (source)
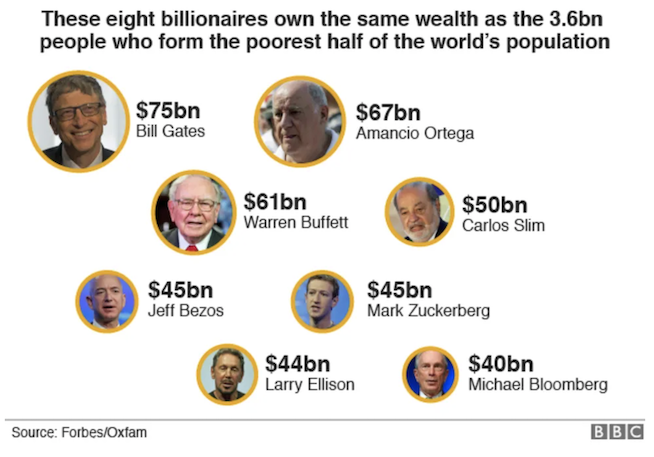
That is seriously fucked up. Almost impossible to fathom, really, what a billion dollars even is. I heard the other day that a million dollars in one hundred dollar bills is 16 inches tall. A billion dollars in one hundred dollar bills is taller than the empire state building.

And I could probably quote about ten thousand Bernie Sanders gripes (he's right), and seemingly countless statistics about how much more expensive university educations and housing prices are, etc., but none of that is a topic here today. I'm just saying that I get it, and Boomers did have it easier than Millennials and Gen Z. Not disputing that.

Wait, where I was going with all of this? Oh, right. Based on my own philosophies and arguments, I'm not qualified, and in no position to write this post! I have been busting my ass on generative AI, but it's really been only 20 or so months. I literally have tens and tens of thousands of additional professional hours that have gone to technology and specifically a number of areas of overlap to what I need to know to be an expert in the topic, but to be crystal clear: those are not hours spent building RAG pipelines or fine tuning models, etc. So I am coming clean here in saying that I (like 99.9% the other 7.9 billion people on this planet) have not been doing generative AI full time for at least 5 years. I'm not even doing it full time right now. Maybe the point is just that I reserve the right to be wrong, but I'm going to give it a shot anyway.
All right, that's enough disclaimers and random thoughts. Let's get into it.
There are so many posts and videos and tutorials out there that have to do with AI. And I agree with Prof G that AI is currently in a bubble. Stealing from a recent post of his:
Of course we are in a bubble now — how could we not be after the mind-blowing debut of ChatGPT? AI is amazing, but the bubble-multiplier effect is very much in play. According to the Economist:
The combined market value of Alphabet, Amazon, and Microsoft has jumped by $2.5trn during the ai boom. [This value creation] is 120 times the $20bn in revenue that generative AI is forecast to add to the cloud giants’ sales in 2024.
That was in March. Now it’s $3 trillion. So the market is valuing AI revenue at 150x. Pre-AI, Microsoft was valued at about 10x revenue, Alphabet at 5x, and Amazon at around 4x. Growing into this AI multiple will require these businesses to find another $500 billion in annual revenue among them, in addition to continued expansion of their non-AI business, the equivalent of adding more than Alphabet’s revenue.
But again, more than one thing can be true at the same time. The internet was a bubble around the turn of the millenium, too, and it still had a greater impact on global wealth than anything that came before it.
In fact, I think AI is going to have such a massive impact on society that we will be forced to undertake a form of universal basic income (UBI). I think it will be negative income tax (NIT), and I think it will only happen once the world collectively hits 30% unemployment or more. Some sort of transition similar to that of the Industrial revolution and automation, but on a far more exponential curve. Am I going to be dead wrong on this? Maybe. But it was less than one hundred years ago (!), during the Great Depression of the 1930s, when unemployment in the US hit 24.9% (1933), and ultimately that led to "The New Deal." I don't know that it will happen in my lifetime, but I do think it's very possible that we'll see the impact AI has as being more extreme than nearly 25% who couldn't find jobs 90 years ago, and I think that's what will have to happen to consider the types of seismic shifts that the likes of UBI and NIT would be, especially in America, which is now an oligarchy (this is a good read). Because it's an oligarchy, money is heavily influencing both parties, and that money represents companies, and companies will be the beneficiaries of AI (in the form of massively more output and significantly less human costs), it is going to take something huge to force change, and 1 in 3 people of working age globally being unemployed is that kind of thing. That ends up with chaos in the streets. To be clear, I do think eventually society and AI will share an existence, with AI doing more and more of the work that currently takes significant human time, and new human jobs will surely be invented, but it often takes a while for those new roles to present themselves and become mainstream (there were no car mechanics in the 1800s). If this feels to you like all kinds of off-topic shit, that's because it is.
All right, so what is this about, if it isn't about gaining expertise via collecting career capital and whether AI is in a bubble, or whether people are going to take to streets demanding universal basic income? Oh yeah, I wanted to explain AI ecosystems! Excellent. There are so many tutorials and videos on RAG pipelines and MOOC classes on the fundamentals of AI, and whitepapers discussing neural networks, and so on and so forth, but I haven't seen many that sufficiently discuss the different aspects of how it all fits together (or even how the basics fit together). I'm going to try and fill that void, because I'm unqualified!
The Overall Ecosystem
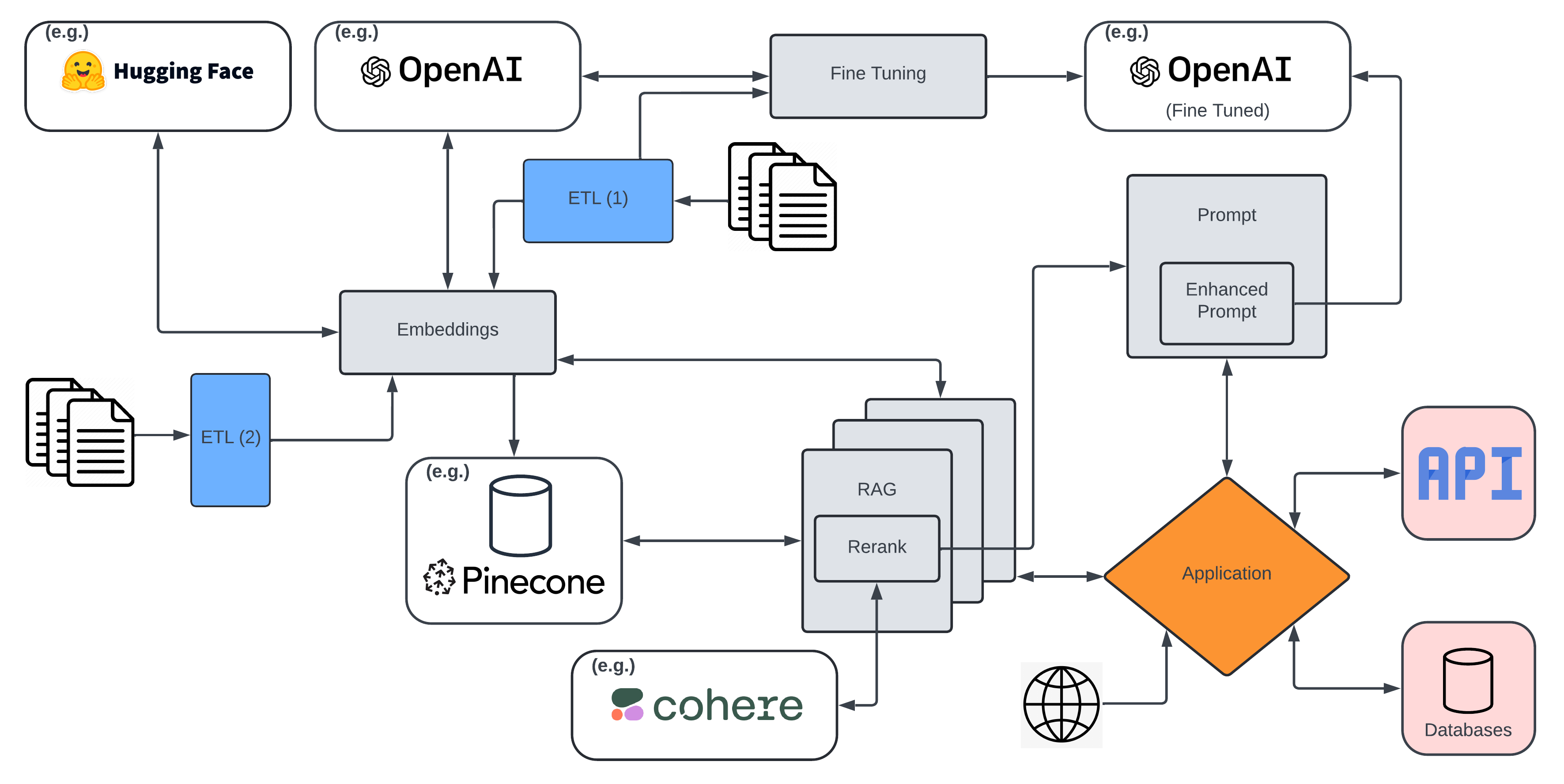
Couple of things before we go further: I am naming names. There are a bunch of different open and closed options for LLMs. There are at least tens of options for vector databases. There are hundreds of different libraries and frameworks that can be used in place of (e.g.) Hugging Face and Cohere. But I think it is all just a bit easier if we use some defaults, and since I use these particular defaults more than alternatives, I am going with this. Plus, because many of them are currently in the team picture of "best-in-class", I think it makes this all a bit more approachable. Want to use BERT instead of one of the OpenAI models? Knock yourself out. You will probably save money along the way, too, if you know what you're doing, at least for now. Eventually, economies of scale may mean that the industry leaders will also be the cheapest, but that's neither here nor there for this post.
There are a bunch of things that could be added to this diagram, and I'm completely ignoring validations of the models or the responses (and a lot of other things), more advanced ways to enhance RAG, and what the techniques are for fine tuning LLMs, but I'm already more than 1,500 words into this and I haven't even started talking about the topic in any detail yet, so let's just get on with it. Just be content with the understanding that there is always more to learn, and no system is as simple as a Solutions Architect may make it seem (guilty as charged).
Finally, as a way of the world's worst legend: I made the functionalities in my diagram gray, such as creating embeddings, fine-tuning, RAGs and prompts. The third party applications (Cohere/Hugging Face/Pinecone/OpenAI) are white, the (generic) application itself is orange and the things it connects to (hand waving over some RESTful API endpoints and some RDBMS, perhaps) are in pink. I'll get into what all this and how it all fits together as I go. For now, that's what the colours signify.
The Application
Not sure if I should start with this one or end with it, but here we are, and there's no eraser to this pencil because I am that lazy. The application could be a wide variety of things, from chatbots to an image based/computer vision application, to speech recognition to predictive analytics/solutions, to name just a few.
In this case, I'm going to talk a bit about something I'm playing with as a means to understanding how all the pieces fit together through practical application. I have always been a huge NFL fan, dating back to when Ted Brown wore #23 for the Minnesota Vikings back in the early 1980s. So, I built an AI-centric application that generates personalised and unique content for me, the user. And maybe my buddy Zeke, who also bleeds Viking purple. Anyway, a couple of times a week, generate a new piece of content specific to the NFL, and in particular, the Vikings, because they're the greatest team in NFL history, though they have never won a Super Bowl and generally let me down, so they have a funny way of showing it.
That content might include a summary of news of the week, any rumours, injury reports, a recap of the week, projections for next week, along with a generated story or blog post. That's basically it. Nothing too crazy, but it requires a bunch of stuff to make it happen, so it is a good (practical) learning opportunity.
Here's a bit of the first blog post that it created. Couple of notes: it's not very compelling content (this was a first cut), and like a text from my sister-in-law, it lacks structure or distinct paragraphs (though this at least includes punctuation), but it is unique content that a LLM (and more) produced, so I'm sharing:
Listen up, you're about to get the real lowdown on the Minnesota Vikings. Everybody wants to talk about the glitzy quarterbacks and sexy edge rushers, but underneath the hood, there’s always something simmering we oughta focus on. So, buckle up because we're taking a dive into the deep, controversial waters of Vikings football.The football world collectively held its breath when JJ McCarthy, the Vikings' top first-round selection, started warming up. And why not? He's the new kid on the block who's supposed to bring the franchise back to glory, and everyone's hung up on every one of his handoffs and dropbacks. Look, you can hyperventilate over McCarthy all you want, but let’s give Dallas Turner his due. This isn't just another pick. The Vikings moved heaven and earth, surrendering more draft capital than a Wall Street firm during a tech bust, to snag this guy. Seven picks, folks. The Vikings have bet the farm on Turner, and anyone who's not paying attention better catch up quick.Let’s break it down—Turner has the kind of freakish athleticism that makes scouts drool. He’s the Swiss Army knife you need on a defense. Sure, he’s got too much energy and needs a metaphorical leash in practice, but isn't that what you want? Controlled chaos on the field? Brian Flores, who’s been around the NFL block, understands what he's got with Turner. Flores isn't just seeing another edge rusher; he's seeing a multi-positional terror, and let’s not forget the last time Flores got his hands on someone like this, he was coaching Dont'a Hightower to Super Bowl victories.Now, let’s talk about the price the Vikings paid. Draft capital, schmraphipal. Who needs it when you already hit the jackpot? The spreadsheet kings are wringing their hands about how the Vikings burned too many picks, losing future roster-building opportunities. Here's the kicker: Adofo-Mensah, the GM who did all this, says it’s part of a grand, all-in approach. Sure, the long-term stability might have taken a hit, but sometimes you have to throw caution to the wind and go for the kill. You play to win the game, right?Alright, so how does McCarthy feel about all this fanfare and noise? From his first 24 hours with the team, he’s throwing around names like Wayne Gretzky and downplaying any QB competition with Sam Darnold. In other words, the kid's cool as ice. Coach O'Connell is taking a slower approach; he’s not rushing him onto the field, not trying to ruin another promising young QB talent by throwing him to the wolves. The idea is to let him grow, learn the playbook, gel with Jefferson—the other JJ—and bring him into the spotlight when he’s ready. Hey, it worked for Patrick Mahomes, didn't it?Ultimately, the Vikings are gearing up for a rebirth. McCarthy and Turner are the new blood meant to reinvigorate a team that’s been teetering on the edge of greatness without quite getting there. If they manage to harness Turner's monstrous potential and give McCarthy enough runway to take off, the Vikings are not just going to be a team to watch—they’re going to be the team to beat. Get ready, NFL. The Purple People Eaters are on their way back.
I'm going to return to this in a little bit. Not Ted Brown. The application. But this is Ted Brown:

And this is the icon I am using for the application:
![]()
LLM
There is more than one in the mix here, but basically, it's the embedding model text-embedding-3-small, a fine-tuned version of davinci, a bit of GPT3.5-turbo in creating the tuning data, and re-rank-english-v3.0 as the re-rank model within the (single) RAG pipeline for this initiative. I could have used a number of different options with minimal differences in the results. Realistically, I'm using the LLM to generate the content, not as a source of information. I think this is a bit of a nuance that is important but that is misunderstood a bit. Generally, when folks talk about AI giving shitty results, it is because they are expecting the data and information to come from the LLM itself, which it can provide (because it was trained on that data in the first place), but what the LLM does is (in terms of conversation) is predict-the-next-word. It's creating sentences on a word-by-word basis, which are obviously coherent and are related to the input, but hallucinations are to be expected when that's approach. Don't get me wrong, it's mind-blowing-amazing. And the way you address hallucinations (some of which you very well may want, depending on what you're doing, mind you, such as when you are looking for out of the box thinking!) is through a combination of things, including the temperature settings and similar configurations, discipline in prompts, RAG implementations, which may provide the supporting data, agents who can verify and/or interact with RESTful APIs, databases, and other data sources, and fine-tuning, to name a few.
Fine Tuning
I asked (the fine-tuned version of the GPT-4o base model called...) ChatGPT to do it for me, and it captured what I wanted to say:
Fine-tuning a large language model (LLM) involves adapting a pre-trained model to perform a specific task more effectively by training it on a specialized dataset. This process starts with a general-purpose LLM, which has been trained on vast amounts of diverse text data. By exposing the model to a new, task-specific dataset—such as customer support conversations, scientific articles, or product descriptions—it learns to better understand and generate content relevant to that domain. Fine-tuning adjusts the model’s parameters so it can recognize and prioritize the patterns and nuances of the new data, enhancing its performance for the targeted application. This method leverages the broad capabilities of the pre-trained model while honing its skills for specific tasks, making it more efficient and accurate in practical, real-world scenarios.
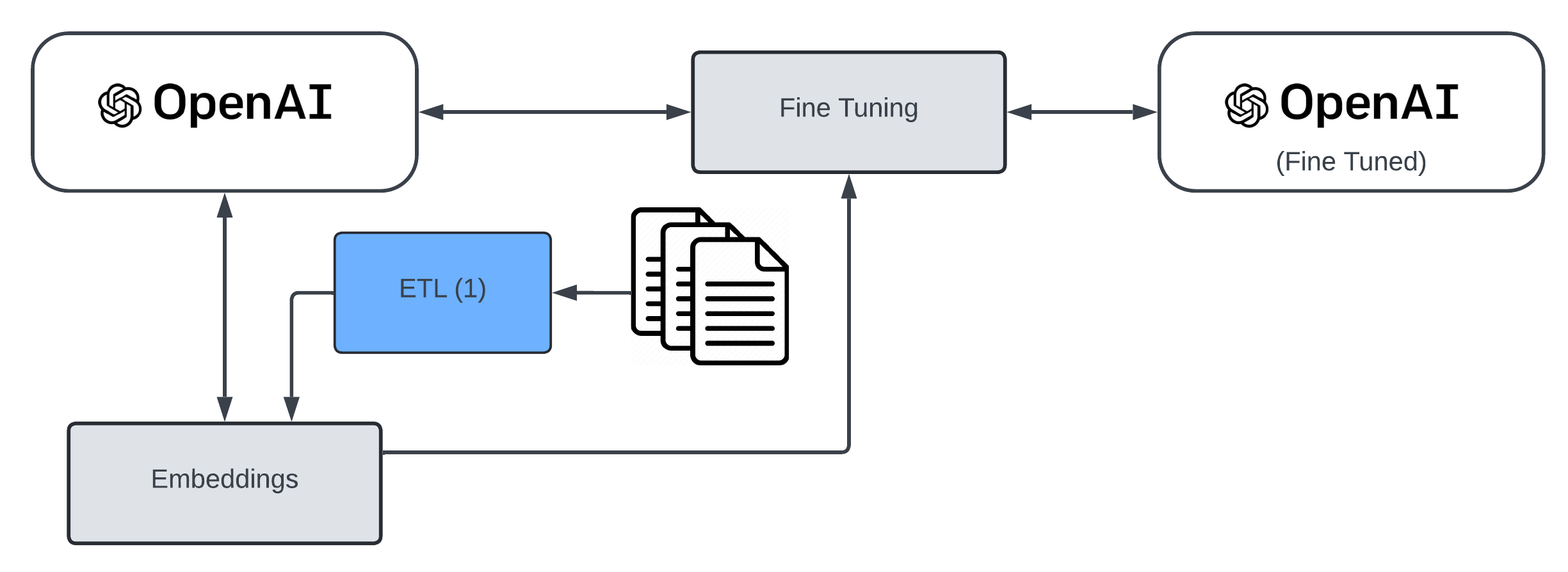
This means the general purpose, foundational LLMs, like GPT-4, BERT, RoBERTa and others are trained by pushing trillions of words through this neural network. And let's just say the output of that is some data/weightings/computer shit. Now, you can take that output and "fine-tune" it by training it further on your data. Essentially, you are specialising it in much the same way as GPT is specialised for ChatGPT or Github CoPilot, to auto-complete code. The best analogy I have heard is that the general purpose foundational model is akin to your GP (doctor), whereas a fine-tuned model is specialised, like a cardiologist.
To be clear, fine tuning is not just taking a bunch of data and adding it to a LLM. Instead, there are different types of fine tuning, including but not limited to:
- Reasoning: This tunes the model to perform logical inference and problem-solving tasks, enhancing its ability to understand and generate structured arguments or solutions.
- Routing: This approach improves the model's ability to direct queries to the appropriate sub-model or external resource, optimizing its performance in multi-step or multi-domain tasks.
- Copilot: This approach focuses on enhancing the model's ability to understand and generate programming code, providing real-time support and suggestions for developers.
- Chat: This tailors the model to generate more contextually appropriate and engaging conversational responses, improving its effectiveness in customer service, virtual assistants, and social interactions.
- Sentiment Analysis: tuning the model to accurately detect and interpret emotions and sentiments in text, enabling applications like opinion mining and customer feedback analysis.
- Translation: This approach adapts the model to accurately convert text from one language to another, focusing on maintaining the nuances and context of the original content.
- Text Summarization: tunes the model to produce concise and coherent summaries of longer documents, aiding in information digestion and content management.
- Named Entity Recognition (NER): involves tuning the model to identify and classify proper nouns in text, such as names, dates, and locations, improving its ability to extract structured information from unstructured data.
- Content Generation: This approach focuses on training the model to create new, coherent, and contextually relevant text, such as articles, stories, or blog posts, based on specific inputs or themes.
In this case, I took a bunch of data from games, stories, analysis, team histories, etc., and I created prompts from it (well, technically, I asked a LLM model to do that for me, then iterated over that list and continued to refine it). That saved me probably tens and tens of hours in-and-of-itself. Anyway, then I provided that fine-tuning data to (in this case) what we can think of as a personalised copy of the output of a davinci model, which adjusted its weightings and became a distinct set of some data/weightings/computer shit. And when I want it to generate a response to some input (say, a question) I now ask the fine tuned version where I used to ask a foundational GPT model (like GPT-4o). So the fine-tuned model is essentially a GPT (transformer) model, but it talks more like a football analyst and it knows more about football. All right, good enough. Moving on...
Vector Database and RAG
Then, I created an index in Pinecone, which is a vector database serving as the backend to a RAG pipeline. I've talked a fair bit about vector databases already, so I won't say too much more here, beyond a really basic explanation.A vector database is a specialised type of database optimised for storing, indexing, and querying high-dimensional vector data. It enables efficient similarity searches and nearest neighbour queries, which are essential for tasks like image and text retrieval, recommendation systems, and natural language processing. Imagine it this way: you take some input, whether it be the sentences in this post (of which that are far too many already) or one of the images in it, like the ones in this ramble, or a video or a song or whatever.
So imagine you take that artefact (text, image, whatever) and you "vectorise it", which is to say you generate a series of...positions a multi-dimensional virtual space.
Then this text/image/video/audio is translated to become sets of numbers, like this:
0.023596194,
0.0040336265,
0.035972014,
0.0019959318,
0.0127934525,
0.025670432,
-0.0344407,
0.015271401,
0.067823395,
0.0058398843,
0.042459227,
-0.046217915,
-0.06515055,
...,
-0.03797665,
-0.0156055065,
-0.015285322,
-0.011554479,
-0.0028572972,
0.020839825,
0.0032349061,
0.043071754,
0.006783036
Now, you've taken something, like the sentence right here (or lots of them), and you run them through an embedding process, based on a specific algorithm for what bytes and combination of bytes should become which numbers, or coordinates, if you will. The algorithm takes these very words, and it converts them to numbers like the ones above. That's vectorisation and embeddings. Embeddings are tied to specific models. I think of the embedding algorithm as the thing that takes the image/video/text/audio as input and generates the numbers like those shown above, but hundreds or thousands of them as outputs.
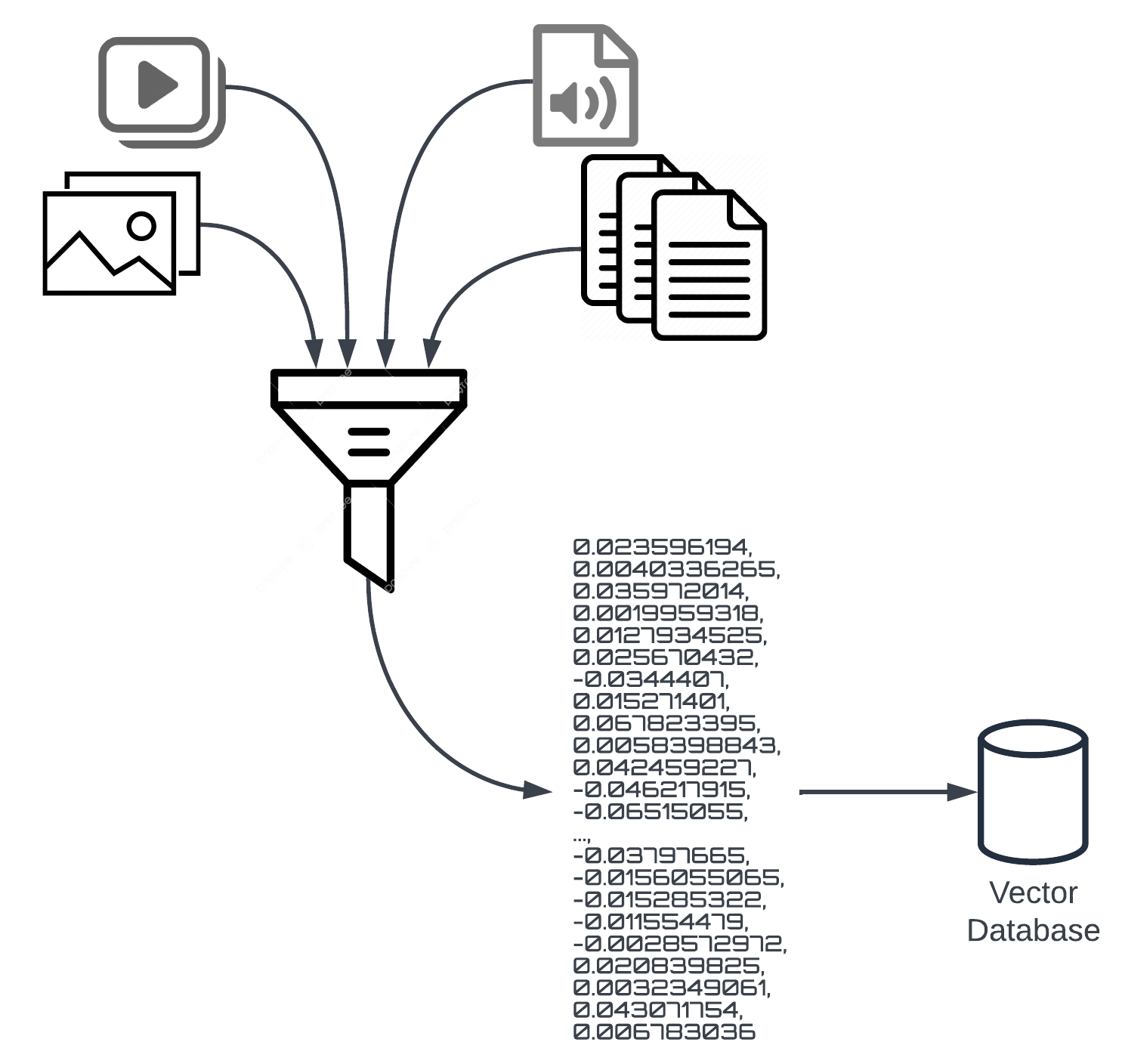
The embedding model and code are the things in the middle, shown as the funnel. And third party applications, like HuggingFace give you access to that stuff, amongst a number of others.
A quick note about Hugging Face: it allows developers to easily leverage state-of-the-art transformer models, such as BERT, GPT, and T5, as well as a community-like hub for sharing thousands of pre-trained models and data sets, as well as AI-based supporting functionalities (some of which I'll talk about here), like fine-tuning, all with a RESTful API layer.
What is important here is that we've used a particular embedding for the middle part, taking our inputs and translating them to some vectors, like the one here, and then I store them into a specialised (vector) database for this type of data, which is Pinecone, but again, insert-your-flavour-here.
To be clear, I say Hugging Face because it's a good library for accessing a large variety of these things, but in my particular case, I chose to use the text-embedding-3-small embedding model for a couple of reasons. First, its compact size ensures efficient processing and storage, making it suitable for applications where resources are limited or where high throughput is required. My driver was the former. Despite its small footprint, it maintains robust performance in generating high-quality embeddings that capture the semantic essence of the text. This model excels in converting textual data into dense vector representations, which are essential for tasks like similarity search, clustering, and recommendation systems within a vector database. And since I'm using this as part of a RAG pipeline wanting to do similarity searches, this was my winner.
One note here: I depict this a bunch of different stuff being thrown into a funnel and all of it gets translated to these numbers and it all gets stored together. That's not accurate. I wouldn't put my blog text and images and videos that were converted because it wouldn't make sense to do that. I'll get to why (below), but for now, let's just imagine we're putting images or videos or audio or text in, not all of them. If I had a situation where I had multiple input types, I'd store them in their own individual indexes within the vector database. Again, not really important here, but I want to make sure I clarify the earlier image. Moving on...
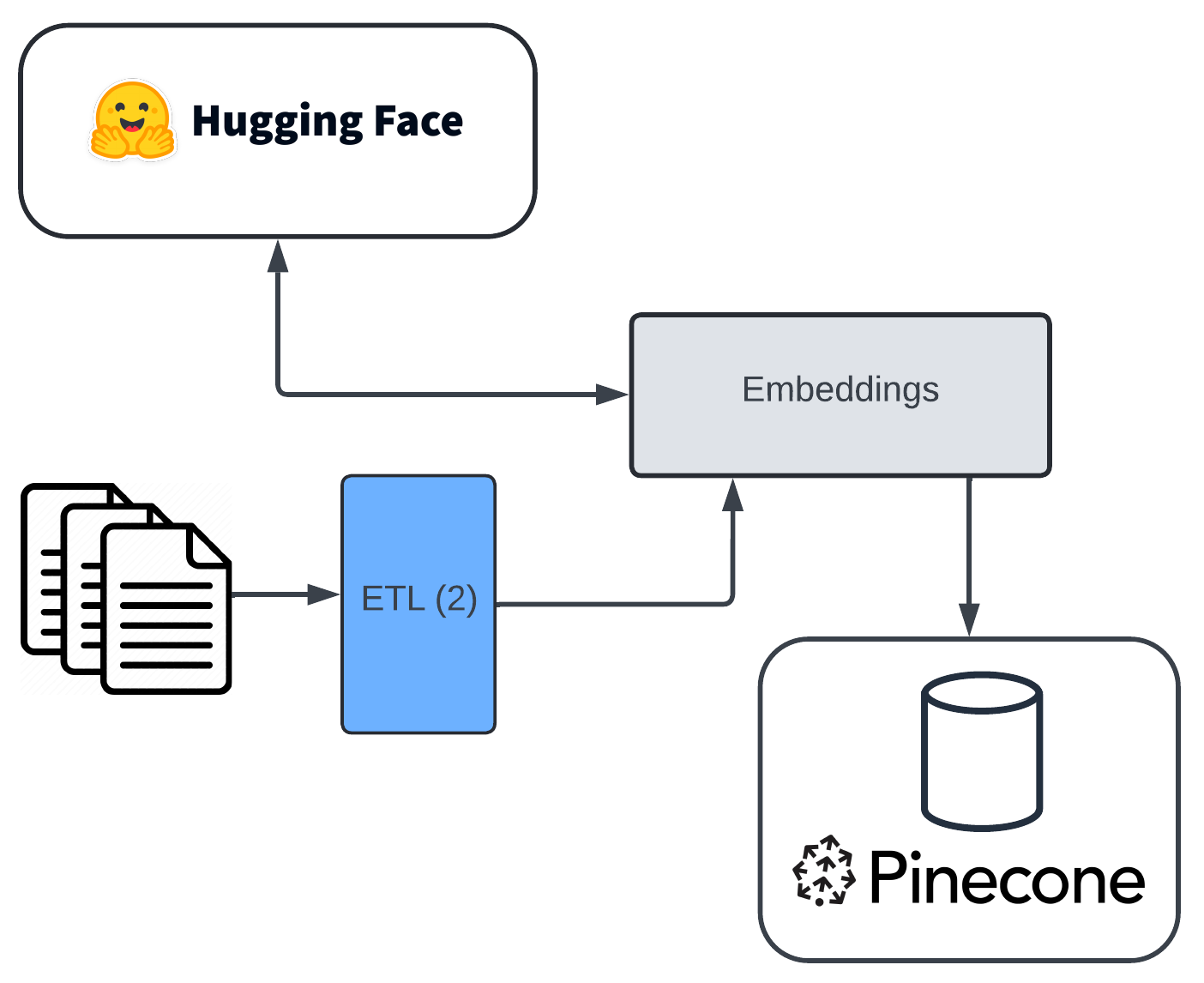
Real quickly, why do I personally prefer Pinecone? In some order:
- the docs are good
- the serverless pricing and the service is good
- James Briggs is an amazing brand ambassador.
But to be honest, I absolutely wouldn't want to get into some meaningless bullshit pissing contest over this vector database or that one. Don't care. Pinecone has a nice serverless offering, and it's the one I have the most experience with.
Finally getting to RAG. RAG, or Retrieval Augmented Generation is pretty simple, though I'm not sure I'll be good at conveying it, but here goes. Now that we have stored these vectors with hundreds or thousands of dimensions each, they exist in this virtual multi-dimensional space, if you will. When you query the vector database, you provide input (which could be an image if that is what we earlier created embeddings of and loaded) or text (same disclaimer), and so on, and how many vectors should be returned, based on proximity to the query vector. Christ, for something I just said was simple, that sure as shit doesn't sound like it.

So imagine that there is this multi-dimensional space (the vector database), and you have created a bunch of vectors (the embeddings) and each of them sits in a location in this multi-dimensional space. When you create the index, you specify the distance measurement you will use when you query it, which is going to either cosine, dot product, or euclidean. Hand-wavy as this may be, here's how you might choose between them:
- Cosine similarity measures the angle between two vectors, focusing on their direction rather than magnitude, making it ideal for assessing the similarity of text data.
- Dot product calculates the sum of the products of corresponding vector elements, emphasising both the magnitude and direction, and is often used in collaborative filtering.
- Euclidean distance computes the straight-line distance between two vectors in space, capturing the overall difference in their magnitudes and positions, commonly used in clustering and nearest neighbor searches.
Now, here's where things get interesting for vector databases (to me), and I know I'm repeating myself, but vector databases are "smart" enough to understand semantic meanings. Good example I have heard before is that you could vectorise the sentence "bees make honey" and put it into a vector database. Then create a vectorised version of the query: "some flying insects that sting produce nectar", and those two vectors would have a near proximity to one another, despite not saying "bees" or "honey" in the second sentence. That's amazing to me! And why does it matter? Stealing my own words from another rant:
Being able to derive semantic meaning and relationships between data points in a high-dimensional vector space is superior to Lucene indexes and simple keyword matches because it captures the nuances of language and context more effectively. Lucene indexes and keyword matches rely primarily on exact word matches or predefined rules, whereas vector representations encode semantic similarities and differences between words and documents based on their context and usage. So I could use these little sweethearts to allow for more nuanced understanding of similarity and relevance, even if they don't share exact keywords or phrases.
Okay, so pretty cool, I can tell you are just like oh, tell me more, random person who already said he doesn't know shit, so I'll keep going.
What these queries are doing is pulling back the closest n, based on the distance options specified earlier, and returning them. So if I do the "bees make honey" query, and I vectorise it using the same embedding model, and specify to return the top 3 closest matches, maybe it returns the following: ["some flying insects that sting produce nectar", "honeybees create wax in their hives", "wasps can also produce substances for their nests"]. Then, we take that data and we pass it along with our prompt to the LLM, and now the prompt has even more relevant information and the fine-tuned LLM can provide us with less hallucinations, and better results. Amazing, and we all celebrate!

Not so fast, bee nerds. Also, why does everyone have glasses on in that image, and so many bowties? Side note, when I asked Dall*E to produce this image, I did a second iteration/request, which was to add some diversity (the first one was all white guys who looked to be between 25 and 35, and may have been from a family tree with only one branch, if you catch my drift). The improvement was that some guys grew beards, it sprinkled in a few women, and...one or two people of colour? Colour me unimpressed, and shout out to OpenAI: you can and must do better, but I digress...
The problem here is twofold (to be clear, I've returned to the topic, and am off the diversity soap box). First, prompt windows can only contain so much data. So if I return 100 items from the vector database, I can't pass all of it. And, overloading the prompt can have diminishing returns. Having nice succinct prompts outperforms long-winded prompt windows (which sucks ass for me, since I'm long-winded). So the solution is obviously to return less items from the vector database (such as the closest 3, instead of the closest 50). But unfortunately, those 3 closest might not be the best ones. Yes, they have close proximities, but what if the 4th (or the 49th) item was more relevant to the actual query than the 3rd, despite the cosine similarity/distance of the 3rd being closer? Let's think of the proximity query as being a large net that we cast. From there, we need to pick out the best ones.
There are a bunch of solutions to this problem, but I am only doing what is probably the easiest one, which is re-ranking.
Re-ranking is a process that takes the initial results from a retrieval model and then applies an additional layer of filtering or scoring to reorder these results based on their relevance to the query. The goal is to ensure that the most pertinent and contextually appropriate information is given higher priority, leading to better quality in the final generated response.
So we adjust our initial query to pull back more vectors. Instead of 3, maybe we pull 30. Then we take those 30 and we re-rank them, according to another query (which could be the same or different than the one we used to query the vector database; for the purposes of this explanation, maybe we pulled from the vector database based on our "bees make honey" query, and now we're going to re-rank based on a tweak of that, like "instructions for raising honey bees", but it absolutely could be the same query and often is). The re-ranking uses a model specific to this task, and simply takes the (in this case) 30 retrieved results and reorders them. Finally, from this reordered/re-ranked list, you take the top 3, and send those on to the ultimate LLM. In my example, I use Cohere for this, but there are, of course, other options.
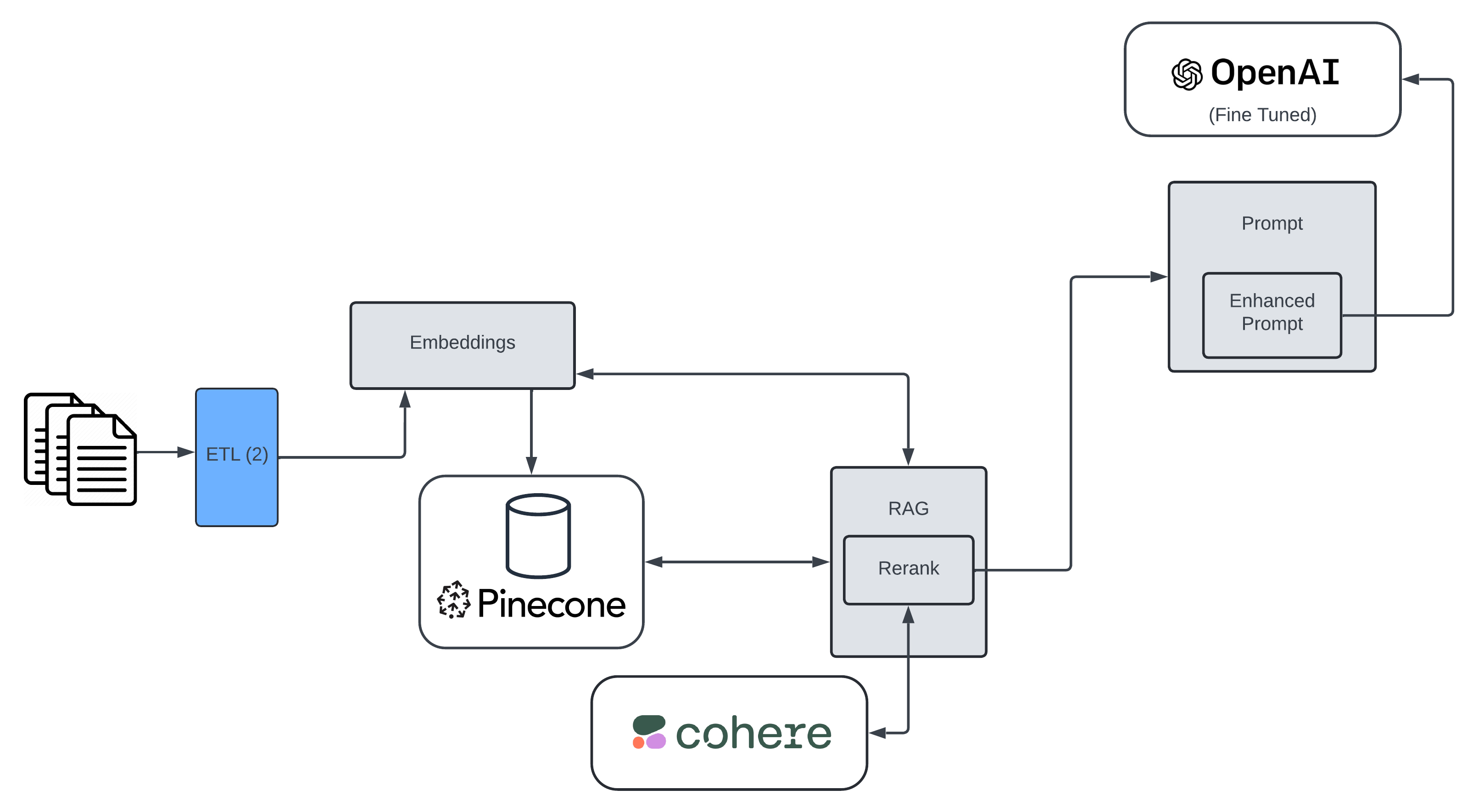
Returning to the Application
Wow, we're almost there. I told you I'd return to the application. Now, we have this fine tuned model, which is better for my particular purposes than the general purpose model was, because I fed it some good examples of what I wanted from it (particularly the ability to generate interesting NFL content). Whereas the foundational LLM was a journalist, the fine-tuned version is a sports journalist, specialising in football (and in particular, the NFL). Then I created a RAG pipeline which will retrieve additional information that pertains to the topic of the content that is being created. Both of those things required that I leverage embeddings for different things (to load the vector database as well as to fine tune the base model). But these things are kind of just the foundation of things. The real magic comes from the application itself, and what it can do.
In my particular case, I've employed a multi-agent setup. In the context of large language models, this enables the coordination and interaction of multiple independent models or agents to achieve a common goal or to enhance the performance of a task. Each agent can be designed to specialize in a particular function, and they work together to leverage their collective capabilities. Agents are independent entities or models that can perceive their environment, make decisions, and act based on their goals and the information they receive. The coordination is the process by which agents communicate and collaborate to accomplish tasks that are beyond the capabilities of a single agent, and each agent may be specialised for specific tasks or functions, such as information retrieval, data summarization, sentiment analysis, or content generation.
So I can create one agent that is the Editor, for instance, and another that is the Journalist, one that is the Statistician, and finally another that is the Researcher. The Editor asks the Researcher to research interesting happenings in the NFL, and specifically for the Vikings. The Researcher requires specialised access for this, to the internet and to an API that provides access to breaking news. The Editor decides from those things which stories are worthy of a blog post, and hands that topic off to the Journalist, who writes the stories and uses the Statistician to retrieve any player or game stats necessary for the story, which in turn means the Statistician must have access to specific data, via an API layer.
Why would you go to all this trouble instead of just expecting the fine tuned LLM to do all the work? A bunch of reasons. Notably: by distributing tasks among multiple agents, systems can handle larger and more complex problems efficiently. Agents can be added, removed, or reconfigured as needed to adapt to changing requirements or tasks, too, so this gives superior flexibility, and finally, it's more robust, as the system can continue to function effectively even if one or more agents fail, as other agents can take over their responsibilities. If you can't tell, I love me some agents...
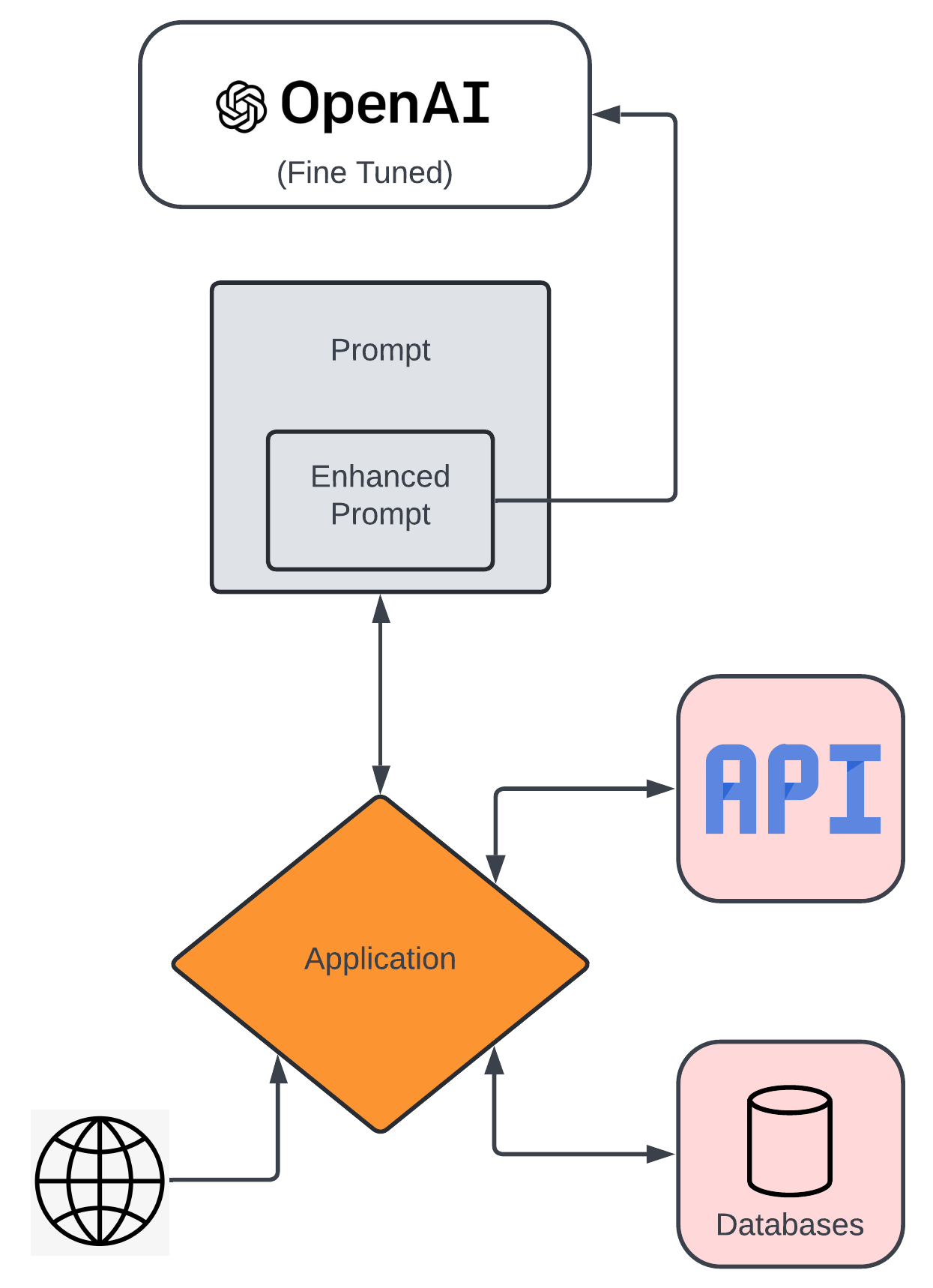
And that's pretty much it in a nutshell, if a nutshell contains more than 5000 words. Big nuts, I guess.

Thanks for reading.


