Joel
JoelDisclosure: All opinions expressed in this article are my own, and represent no one but myself and not those of my current or any previous employers.
All right, my last post was really fun to write, even though it swerved completely out of my professional lanes and strongly towards my outside-interests. This one might not be as fun to write (and let's be honest here, rarely are any of these cohesive enough to enjoy), but it's very much in my lane; in fact, it's a highway I commuted down for about twenty years: Data and Analytics.
I've written tens of thousands of words on various topics under that umbrella, and most of those were written as I was actively working on those things, or had accumulated significant career capital doing them over extended periods of time. When I was a Data Engineer, my posts were focused on the transition away from RDBMS to cloud-native approaches, where decoupling compute and storage was a fundamental aspect to the solution (something I'll quickly recap), data processing in distributed systems, and so on. Prior to working exclusively on cloud based solutions, I had been focused on a more traditional tech stack, particularly ETL patterns, and RDBMS databases (from the design of the data models to the performance/optimisation of the database, to the processes that execute on those databases, both ETL and ELT, to the data visualisation and reporting that executes on top of it), and across all of those learnings, how to do it for data science/machine learning, and in particular, how to do it all at significant scale (and scale that continuously shifts one direction, with hockey stick bursts).
I cringe at some of the things I wrote when I glance back at earlier posts. Case in point, I've become the biggest advocate for single-table-design, particularly in DynamoDB, but my earlier writings make the cardinal sin of essentially replicating a relational design using a wide key-value store. Sadly, also not my worst cringe, by some stretch, but let's look forward instead of rehashing my ridiculousness. Oh well...
When you look back at yourself six months from today and don’t feel embarrassed by your naïveté, there’s a problem.
-Ryan Hoover
What is new this time is that I am writing about the Data & Analytics space with the passage of time, and seeing now what that discipline has become, and how it might be interesting to step back and apply some old patterns to simplify new(ish) problems and nuances to old problems. But before we get there, we have to figure out how we got here, at least through my lens. Of course I'm going to take a multi-faceted and complex problem/solution and over-simplify it, but you'll appreciate that, because I'll inevitably use too many words to explain things than I need do, which I'm already doing here, so...back to it.
I'm going to try and explain both how and why I think we've lost our way, and why the three V's of "Big Data" (Velocity, Variety, Volume) aren't excuses we can use any longer, and why we have a new definition of Variety that we need to accomodate, while getting back to the basics and reinforcing those required (and lost) skills.
I won't go back too many decades before anyone reading this was probably alive [fucking sigh] but some bits are important because they are part of the history that has driven how we build things now, and are one reason why we find ourselves buried in technical debt (or creating it...) and a seemingly never-ending "under-construction" project so many Data environments we encounter seem to be. We can connect the dots when we look backwards, -n-shit.
Disk Used to be Expensive & Data Models
Anyone who has heard me rant and rave about this will roll their eyes at hearing it again, but disk used to be expensive. In 1980, a single gigabyte of disk cost between $250k and $500k USD, or more. By 2020 that cost had decreased to under five cents.
In large part because disk was expensive, it was important to minimise the number of copies of any piece of data would be stored to the hard drive, if you will, of the server, because servers have finite storage, and storage was really expensive. Perfect world, you have every piece of data, whether that be a customer name or the transaction of buying a shirt with a credit card ending in 1234, written to disk just one time (setting aside backups and replicas and other disaster mitigation and legal requirements), because that makes it the least expensive, and because that opens up space to store more data, and more data is always better (NOTE: it's not. Please read Nexus, by Yuval Noah Harari).

Relational Databases
This gave way to a discipline around relational database modeling. From Wikipedia:
The relational model (RM) is an approach to managing data using a structure and language consistent with first-order predicate logic, first described in 1969 by English computer scientist Edgar F. Codd, where all data is represented in terms of tuples, grouped into relations. A database organized in terms of the relational model is a relational database.
We won't get into the history of it beyond that, or Edward F. Codd, pictured here:

Wait, check that...this is him:

In any case, I bet a six pack of beer with that guy would be fascinating. We'll at least mention that as part of the amazing career of work to his credit, SQL is included. The point of this post isn't going to be technical at all, but we can think of SQL as the natural programming language to interact with a relational data model. Love it or hate it, it's a vital component and a must-have skill for every Data practitioner.
So we had this expensive disk, and so we used relational models to minimise the amount of disk that is used, thereby allowing us to have more diverse (in terms of more tables and columns) and additional data (more rows of it). Then in the 1990s some really focused work and techniques emerged from a guy named Ralph Kimball, who I am LinkedIn to, which makes me very, very cool, obviously.

Stealing more Wikipedia content from his page
Ralph Kimball...is an author on the subject of data warehousing and business intelligence. He is one of the original architects of data warehousing and is known for long-term convictions that data warehouses must be designed to be understandable and fast. His bottom-up methodology, also known as dimensional modeling or the Kimball methodology, is one of the two main data warehousing methodologies alongside Bill Inmon.
He wrote a book primarily about analytics data modeling called The Data Warehouse Toolkit

that everyone had read, and generally stuck to in principle, but tweaked/ignored/added to as needed. A lot of the concepts and understandings about modeling data at scale are the same as they were here, but creating things like updates in RDBMS on immutable disk and in distributed systems has challenges. The principles and patterns are still applicable, though, and the skills are deteriorating, and we're paying the price.
Recapping and connecting dots: we have this relational model foundation (Codd), largely as a response to the costs of disk at the time, and now we have another focused data warehousing discipline from Kimball, called dimensional modeling, or star-schema, because of the way a table sat in the center of many shared satellite tables, containing measurable "transaction" data, in what are called "Facts". Those facts are transactions with event and largely numeric characteristics, like "price: 50", and they all happened at a time: "purchase_date : 20240927", or some combination. These are purchases at a store or claims in insurance or view details of a movie, to name a small few of many types. These are basically verbs, if you want to think of it that way (e.g., a purchase, or the entering a claim, ...).
But they also have characteristics that if we added to every transaction, we'd be wasting disk replicating the same things again and again. Simple example, we wouldn't want to add the customer name to every single transaction that a customer might make, because it would be very disk-expensive. Even for my own name, it's ten letters per instance, but for my friend Manjunath Venkataswamappa, it's twenty-four bytes. Also, he has just about the coolest name ever, and that matches him as a human, in case you were wondering. In any case, once we add the addresses to the transactions and the credit card information, etc., that's another couple hundred or more. So instead, we assign Manjunath Venkataswamappa a customer number, because integers take up less space than string data (e.g., letters). So now Manjunath is customer_id 12345. And we store "Manjunath Venkataswamappa" only once on disk, in the customer dimension and then when transactions come in, with price:50 on date: 20240927, we just store customer_id: 12345, and then you join your fact table to the dimension table to retrieve the customer name or credit card information, etc., on an as-needed basis.
And those dimensions are organised by type, so you would have a customer dimension and an address dimension and a store dimension and a product dimension and a movie dimension, etc. You can go so far as to even have your dates as a dimension, and instead of storing date: 20240927 on the fact, I have a date dimension that gave that particular date the "surrogate" value of 56301, and instead of storing the bytes 2-0-2-4-0-9-2-7 on disk for every transaction of that day, I instead store 5-6-3-0-1 on each transaction and save 3 bytes per transaction. That probably seems ridiculous, but by the time you're processing hundreds of millions and billions of transactions, those types of things could save an organisation literally millions of dollars, at scale (a conversation we'll get to soon, I promise). Dimensions can be thought of as a noun (e.g., product, customer, ...). Here's an overly-simplified dimensional model, so you can get the gist of it.
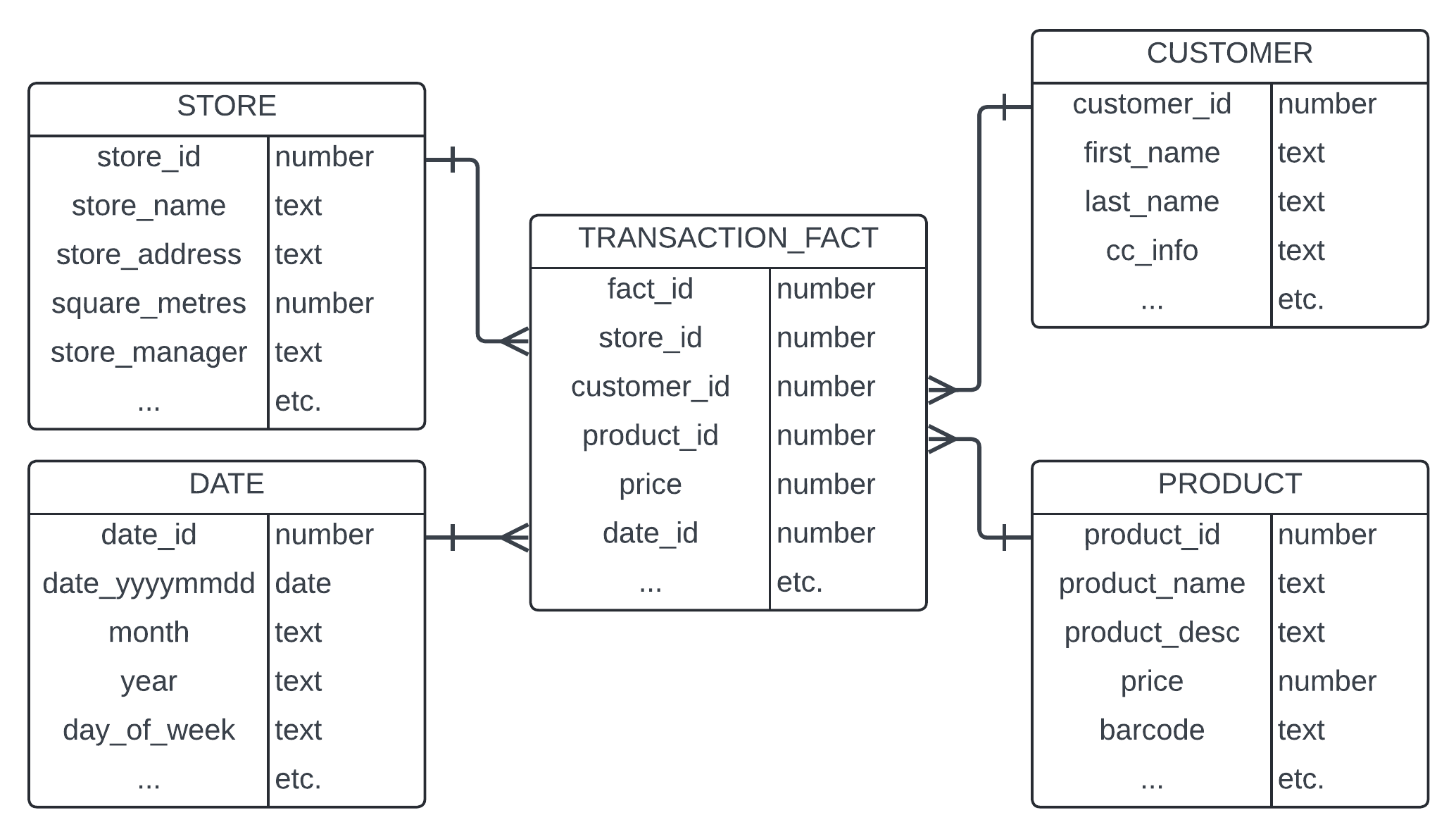
This discipline of data modeling, and specifically, dimensional modeling for Data/Analytics as it grew from "Business Intelligence" to "Data Warehousing", which was both a rebranding of Data as well as a shift that was based on an increase in volume. This is when we got into (single digit) terabytes of data. That was what the technology of the time, and the budgets of the time, allowed for. But that is the very discipline is what truly drives self-serve environments. It's not the tools you put over the top of it or anything else. If the political phrase is "it's the economy, stupid", than the data equivalent is "it's the data model, stupid" (shout out to James Carville).

Because everyone can understand a solid foundational data model, that equates to more trust, and less need to hand-hold. And, vitally, if your data model is accessible, that means it requires less tribal understanding, which is best for a number of reasons that don't (necessarily) include: "that's Bob in the corner. 32 years ago he wrote the VB script in Excel that the entire banking industry in the country runs on. He hasn't had a chance to write the documentation yet. Don't approach him about it because we can't afford for him to quit or get sick. Generally, just don't approach him ever." Tribal knowledge in Data environments exists when you need help knowing which tables to access certain information from, you can't write the query yourself (whether that be SQL or by a drag and drop or click-click-click set of reports), or you're hiring people who act like a liaison between the underlying data structures and the usage of it. If any of those things are you, my recommendation would be to make that investment, all things being equal (which, of course, they never are. Maybe I should say: "some restrictions apply").
Data Visualisation
Data Visualisation/Reporting/Dashboards are all names for using charts that convey a narrative, act as a means by which to identify trends over time, or in comparison of multiple things, and an invaluable tool by which to find trends and the signal in the noise. One of the best data visualisation books out there is surely The Visual Display of Quantitative Information, by Edward Tufte,

but for a more accessible work that I personally prefer, try Information Dashboard Design, by Stephen Few

(or anything else he's written). What is important to note about this important skill (and one I don't think enough people truly specialise in...a rant for a different happy hour), is that the tools that people have used to do data visualisation have relied on relational models (and preferably dimensional models) for decades. This was true of Business Objects in the 90s/00s to MicroStrategy in the 00/10s to Tableau in the 10s/20s, to name just a few of the dominant ones of each era (even many of the terms in dimensional modeling have made their way into these tools), and it will be true for the next wave as well. While the tools of today accomodate other underlying structures, they still prefer a dimensional model.
While all of this was happening, the price of disk was continuing to come down, and organisations were leveraging these data modeling and data engineering disciplines to store and process more and more data, which then can be used to do many interesting things, including statistical analysis of data that didn't fit into Excel, and the valuable data visualisations over the top. Disk Price --> Relational Model --> Data Warehousing --> Dimensional Model --> Data Visualisation/SQL.
And because we were doing a good job of storing more and more data and making it really accessible, we started to be able to do more and more interesting things. We could start to use it for machine learning, for instance, and of course as the price is continuing to decrease for Data, it's falling for everything else, too. Products are evolving. Data is becoming the centrepiece of products. Time for another rebranding and transition; it's time for Big Data...[insert vomit emoji here].
Big Data
The vomit emoji is because of the term, not the usage/practice. The issue with the branding is that you have nowhere realistic to go after that. What...bigger data? Biggest? Most Biggest-est? Never work on a project that includes "next generation" as part of the internal acronym, either. Red flags. I need a beer.
Anyway, I've been lucky enough to get to play at the forefront of the explosion of data, across retail (Nike) and financial organisations (Citi, then later with Commonwealth Bank of Australia, amongst others), and then at the bleeding edge of Big Data/Cloud, with Netflix during their transition to the cloud and in other Silicon Valley organisations. That's not intended to be a resume brag so much as examples of where I was lucky enough to play with petabytes of data, and to provide support that I'm not completely full of shit, even if I am.
It was during these times when the price of disk had approached zero, and that meant that it became imperative to decouple your compute and storage. The storage didn't cost anything (comparatively) and simply continued to grow, but the compute needed to ebb and flow (and burst) to process more data, and those costs continued to increase (or, more actually, the chips kept getting better, and the better ones were more expensive. The point is the same). Compute was volatile, despite obvious patterns. Compute was high during the day and lower in the evening, when less people were working, for instance. Two other things happened during these very interesting times, that I'll call out.
Data Swamps

First, we created "Data Lakes" which weren't actually all that new. We just learned how to dig them deeper. We always had "raw" and "processed" data, and Data Lakes are, for lack of anything else, raw data from various disparate sources, prior to being cleansed or formatted or organised or modeled. The only difference from the raw data areas in the RDBMS systems of the 2000s and those of the 2010/2020s are that the former had more limited space (tightly coupled with the server of the RDBMS) and that the latter was not RDBMS, per se, which allowed it to contain a much larger variety of data. Most frequently, that was key/values or JSON, but it could be all kinds of things that don't neatly fit into columns and tables of traditional RDBMS (images, audio files, etc.). And all of that was on top of the data that was being cleansed and validated and being served up under the more disciplined model. Like giving your child a larger room...expect a larger mess. There's nothing new here other than space and variety, and more data means more stuff to maintain, cleanse, organise, observe, report on, archive, and so on. But don't pretend this was a new problem. It wasn't. It was just a different characteristic (more volume) making an old problem seem new.
Secondly, we adopted cloud technologies. First, it was the classic lift-and-shift, taking existing (e.g.) Oracle or SQL Server databases and hosting them in AWS or Azure. Nothing was necessarily different, but they weren't servers we were managing on site any more. Instead, they were in "the cloud." And as part of that, the Data Swamps could be in more inexpensive storage that was also able to accomodate the larger variety of data, be it JSON, csv files, PDFs, videos, audios, whatever. Most often, when you hear people piss and moan about how the cloud is more expensive, this is the cause. They aren't embracing cloud-native, they're doing the exact same thing as they did before, sans the depreciation aspect and using a different billing model, and yeah, that is more expensive, but you're also doing it wrong.
But let's be clear: the old stuff was the new stuff, but kinda different (in hindsight) and significantly different (in the moment). The model on the database was still the same, the RDBMS itself was still the same. The data model was the same. The data visualisation was the same. Sure, there was now this hosting difference (the cloud), and we added a S3 Data Swamp, but it still barked like a dog.
Then, when the data got to be too much for our Postgres or Oracle single server, and we had to find other ways to do it. First, it was the likes of ParAccel, which AWS bought and rebranded as Redshift. Other options included a cloud-based Teradata. Eventually, all the cloud providers have a service in that niche. This kept everything almost exactly the same, but instead of being on a single server, it was on a cluster of servers. This meant that the model would change slightly (if you deeply knew what you were doing. Very few people did, and that is a major reason so many people hate Redshift). It meant that data had to be shuffled from server to server so that you could accurately aggregate data and get to a single answer for questions like "how much were our sales by product yesterday?". But, we were still tightly coupled (disk and compute), it was just lots of servers, so the problems were the same. And you had redistribute the data every time you added a node to the cluster, etc., and it was all more complex and more expensive than it used to be.
Where most places get that wrong is that the default distribution key is often the surrogate in what we used as the join keys in the dimensional model. I'm going to over-simplify this so I don't get more distracted, but this naturally leads to more shuffling, so then you do other things, like data co-location, but then the nodes in the cluster get unevenly distributed, and then when you eventually run out of space on one, you're adding more nodes to the cluster, and then you have to redistribute the data, and if you're in Redshift land (back then, anyway) you had to do this "vacuum" cleanup for all the shit you left lying around while you were doing the upgrade that just left everyone on a range from pissed off to PTSD. But at least now it would be more expensive, and we'd be doing this again in a few months, but next time, it'll be better. NOTE: it wasn't. And the discipline of data modeling moved from being the art of it to something you could skip over if you threw enough resources and money at it. And in the process, a step away from real self-serve was unconsciously made. Slippery slopes.
Then places like Facebook and Google and Netflix and Amazon and others started to generate more, and want to strategically leverage more, of their data (beyond dashboards that reflected financial numbers), and tightly coupled compute and storage wasn't cutting it. So then Facebook created Presto (now Trino), which was essentially an abstraction of a RDBMS that was transient. You could provision a cluster to do computation and connect it to decoupled storage. The disk of the storage had the raw data, organised. And the metadata for how it was organised was persisted elsewhere, and when you provisioned a cluster of servers for computation, you could "inherit" the metadata (if you will) and then you'd be able to make sense of the data on the decoupled storage (e.g. S3), and then when you were done with your query or your day or your model training, you'd write the results back to the decoupled storage and terminate your cluster. Doing it that way you paid only for the compute you were using (and only when you were using it), and the persisted (decoupled) storage was comparatively free, so you could effectively infinitely scale your disk (storage) and provision whatever compute you needed on-demand and terminate it whenever you wanted. AWS saw the opportunity and rebranded Presto as Athena and managed the EMR clusters that it was installed on, but...I mean...samesies with polish, and as a managed service. Bark bark.
It was throughout this time that the likes of Apache Pig and Spark and Flink had their day, and also when related compute and frameworks like Kafka had theirs, in terms of being the go-to technologies while we were all figuring out whether being cloud-agnostic mattered. Complicated discussion, but no, the juice isn't worth the squeeze. To be clear, all those things are still around, and if you're using them regularly, I'm sorry. It's not that they're not impressive and powerful. They are. They're also incredibly frustrating for all kinds of reasons. It's okay, practitioners, you can admit it. It'll make your shoulders feel lighter.
Now, because the RDBMS was out of the mix, the data model on top of it has flown out the window. After all, one of the major drivers of those data models were because disk was expensive, and now disk is comparatively free, so sure, that model should change. My problem with it is that we threw out the baby with the bath water.

Enter the 3rd Party/Vendor Platforms
I told an Account Representative from AWS once that I considered their Data offerings to be "an abortion." He snickered, then nodded and somewhat sheepishly said that they hear things like that a lot. Seriously. Glue is a brutal abstraction of Spark. Athena is just Presto. Redshift is just ParAccel. Glue Catalogue is just an externally managed Hive metastore. And QuickSight is shite. I love AWS and what it's enabled and provided me in my life. And that's also why I have to be honest about that. I wish I felt like they'd turned a corner and were going to right the ship, but SageMaker never fully cut it, Serverless EMR is only partially there, and so far my experience with Bedrock makes me "roll my own" AI solutions. In short, more of the same, so far. Very different than things like DynamoDB and Lambda, which seem to get better engineers working on them, or something. And it's not an AWS problem; none of the major cloud providers are able to get their products to compete with third party platforms. And now it seems like the only things out there vendor lock-ins. For whatever reasons, migrations to the biggest commercial Data platforms are huge undertakings. The promise is everything is solved for you, but it takes a multi-month investment before you say "...hey, wait a second...".
There was a void, and third party platforms (specifically Databricks and Snowflake) stepped in and filled it. I have no problem with these platforms, per se, but let's be honest about what they are: abstractions of all the stuff I've been talking about above (now with many more bells and whistles!). At various stops I've leveraged these (more hands-on with Databricks than Snowflake, admittedly) in various capacities, but we tried to avoid them unless there were mitigating circumstances. A lot of people disagree with me on this, but I find that at the end of it, it's never delivered for me the promised land that it sells itself as. And it is always an expensive lesson to learn. Kinda like Salesforce. Anyway...we could accomplish all of the same things with (creating and using) open source frameworks to provision and terminate and monitor and log (etc.) the clusters of compute and we created ways to schedule (orchestrate) on them, and we created ways and frameworks to leverage (e.g.) Apache offerings and other open source tools and applications to process data, monitor processing, secure, etc. And then we used best-in-class visualisation applications and so on for reporting.
In short, we mostly rolled our own. And we were able to do that because we had amazing staff, and because we deeply understood the things I'm rambling on about here, or because we were feeling our way around the elephant.

Still not sure why Dall*E blindfolded the elephant itself...anyway, because we were really working at scale and a lot of these things didn't yet exist. At one point, I was tasked with re-architecting a system for Data Analytics, Reporting, and Machine Learning uses for the daily watch data at Netflix. Pretty much heartbeat data, so it was huge, for the time. Every few seconds a "fingerprint" of each person and what they were watching and where in the movie or show they were, etc. When I was lucky enough to get to play with that, if we missed a day for any reason (such as a process failing overnight), we couldn't catch up. The old technology and approaches were not robust or scalable enough to process the data fast enough process two days in 24 hours. At the time, Big Data stuff in analytics and data science. We had to be innovative because we were paying the ultimate pioneer tax of the times. And along that path we (certainly I) made a hundred bad decisions or good decisions that turned out bad. So the pioneer tax has a range to it, and at one end, it hurts a lot. Later on, after things matured and you could understand where a specific technology fits in an overall ecosystem, these things can be assembled together, positioning each one as a specialisation, but that's far beyond the budgets of the vast majority of companies!
But I can completely understand why firms without deep knowledge (or, perhaps without a desire to roll your own, which absolutely has its own costs that aren't necessarily invoices coming in each month), and Snowflake and Databricks do MAJOR parts of that for you. The red flag in your organisation is either that your staff has no experience/doesn't know how to roll their own (an indication of a skills issue), or they say things like "we don't want to deal with the plumbing, we want to make use of the data", which is correct, but they're discounting just how much plumbing they're still going to have to do. Unfortunately, is no there is no free lunch. Rather, just as we hoped the likes of Redshift would eliminate our pains but only created others, so do these third party platforms.
All of this transition was centralised around the problem of the data became too big. I cringe because the name "Big Data" is...just...so...stupid. But the definition is vital, because it drove so much, so stealing from Wikipedia a third time:
Big data primarily refers to data sets that are too large or complex to be dealt with by traditional data-processing application software.
That's the first sentence, and the meat of it all. The volumes of data were too large to utilise the technologies we'd grown up with. Single server RDBMS ran out of disk. Clusters of servers couldn't keep up with the processing, what with all map/reduce-esque processing, shuffling, and the like.
So all these new appliances came on-line and the techniques that I called out above became the rage, and we threw more and more compute at the problem, and we ran benchmarks and compared (e.g.) whether fewer large servers were better than lots of small servers (they are, by a wide margin), and we optimised YARN and turned the proverbial knobs on memory per node, and optimised underlying structures using emerging technologies and frameworks. Hive went through many iterations. Hadoop fell out of fashion (while we continued to replicate the strategies that underpin it), as did certain pipeline technologies (like Pig) as the focus changed from proprietary languages to abstractions (e.g. you can write Python or Java Spark, amongst other things), and the focus turned more to real-time, micro-batch, and mini-batch.
Velocity: "Right-time" Processing
That last part is kind of important, so I want to quickly talk about that a bit more. During these wild times, while technologies were changing, abstractions were being built, data swamps were growing (and growing more and more polluted), we saw Flink and Spark (in particular) win the battle for "real-time" processing. I use the quotation marks there because very often it's not pure/true real-time, but it's close enough. Spark used micro-batch for many years, for instance, which were little tiny batches of data, which could be configured to be within a second, but it wasn't true real-time (that has since changed). I tend to think of these solutions as "right-time", since for your organisation and for your specific use-cases, it's often just fine to have data available within a fraction of a second. Or, every minute. Or every fifteen minutes. Or every hour. It depends on what you need it for, and whether data seconds or minutes earlier would actually change anything. It sure does if we're landing an airplane. Less so if we want to monitor where our food delivery or Uber is. Being a second behind in those scenarios isn't the end of the world.
Patterns
Certain architectural approaches were emerging, too. I was very interested particularly in the "Lambda Architecture ", by Nathan Marz (who also happened to write the Manning book titled Big Data),

and was the creator of Apache Storm, which clearly makes him an over-achiever. In any case, the Lambda Architecture (NOTE: not to be confused with AWS Lambda functions in any way!) was borne out of the How to Beat the CAP Theorem post. I am going to call out specifically the final paragraph of that post:
A lot of people want a scalable relational database. What I hope you've realized in this post is that you don't want that at all! Big data and the NoSQL movement seemed to make data management more complex than it was with the RDBMS, but that's only because we were trying to treat "Big Data" the same way we treated data with an RDBMS: by conflating data and views and relying on incremental algorithms. The scale of big data lets you build systems in a completely different way. By storing data as a constantly expanding set of immutable facts and building recomputation into the core, a Big Data system is actually easier to reason about than a relational system. And it scales.
Fascinating here that he (correctly) calls out what folks were really challenged with: "we were trying to treat 'Big Data' the same way we treated data with an RDBMS", and the ways that scale changed things: "[t]he scale of big data lets you build systems in a completely different way." We were different and we were dealing with different problems because our scale was so much different than it historically had been! We were now using new and different technologies. New and different frameworks. New and different storage mechanisms. New and different architectures. And the Lambda Architecture promised to be one of those that delivered us to the promised land.
The Lambda Architecture
So what was the Lambda Architecture, if not the AWS service? The Lambda Architecture is (was?) a data-processing framework designed to handle large-scale, real-time and batch data processing. The architecture divides data into three layers: the batch layer, which stores all incoming data in its raw form and computes pre-aggregated views over time; the speed layer, which processes real-time data to provide low-latency updates; and the serving layer, which merges the results from both the batch and speed layers to deliver final outputs. This approach ensured robustness and fault tolerance by separating the batch and real-time components, allowing for accurate and up-to-date data analysis.
That all sounds good, of course, and makes logical sense. We'd combine emerging technologies with tried-and-true patterns. We could introduce NoSQL for the (near-)real-time (playing to it's strengths), and traditional batch-writable, random-read databases, though with different modeling techniques, specifically designed for the massive volumes we were processing. However, the Lambda Architecture faced criticism and fell out of favour due to several challenges. One of the major issues is the complexity of maintaining two separate codebases (for batch and real-time processing), which leads to higher operational costs and development overhead. The redundancy in logic between the batch and speed layers can also introduce inconsistencies. Finally, as stream processing frameworks (primarily the ones I've mentioned already: Apache Flink and Apache Kafka Streams, Apache Spark) made it possible to achieve low-latency, accurate results without the need for a separate batch layer, thus simplifying the architecture. So while the point he makes that "[b]y storing data as a constantly expanding set of immutable facts and building recomputation into the core, a Big Data system is actually easier to reason about than a relational system" may have had some truth to it as things were evolving, the solution ended up being more complex than it needed to, and once the technologies caught up, the complexities of the architecture outdid the benefits it was trying to solve for.
But the ideas were right. We were combining the old with the new. The fact that the shift towards unified, (near-)real-time data processing made the Lambda Architecture less popular in modern big data applications doesn't mean it failed or didn't work; rather, it means that as things continued to evolve, we took parts of ideas and continued on, applying patterns in new ways. The point I'm trying to make here is that AS WE LEARNED MORE, WE EVOLVED AND WE DID THINGS DIFFERENTLY, which of course, the correct response is: "no shit."
And that brings me to an important point here. Things have further changed, and we should take those changes and apply our patterns differently. Let's return to the very definition of "big data":
Big data primarily refers to data sets that are too large or complex to be dealt with by traditional data-processing application software.
As a friend and former colleague of mine is apt to say: you don't have big data. And he's increasingly right with each passing day, especially if we use, well, the definition.
New Zealand
I've been living in New Zealand since 2019, and in that time, I've met a lot of people who run Data & Analytics consultancies, and who work in Data & Analytics departments. I've even created my own of the latter, and I will be the first to admit the mistakes I made in doing so. I didn't appreciate the fact that nobody in New Zealand has big data, and in particular, I was implementing the patterns, techniques, and technologies as if it we did. I won't defend my reasoning, but I will at least explain it. You see, in the company I founded in the States, we had two heartbeats: one was a professional services practice, who specialised in designing and implementing modern day, "infinitely scalable" data environments, and one that was product focused. I tended to think of the former as the means that enabled the latter. The former was also where I'd accumulated the most career capital (see earlier career discussion). So it was only natural for me to see a greenfield opportunity and to promote and push decoupled compute and storage. It was only natural for me to push the (Apache) versions of the technologies I had gained expertise in (such as Spark), and avoid the "abortion" of an abstraction that was Glue. It was only natural for me to want to "roll my own", since I had far more experience doing so than anyone I would likely encounter representing the third-party/vendor solutions, and anyway, why would I pay them to do exactly what I already knew how to do anyway?
But by our definitions, New Zealand sure as hell doesn't have big data. RDBMS technologies have advanced light years, and can handle significantly more data than ever before. In fact, what we've seen happen by the cloud providers is that they've focused on abstracting away the things that made it not scalable. When people talk to me about RDBMS solutions and pushing the boundaries of scale using those technologies, they often use a trigger word for me: sharding. Database sharding is a technique used to horizontally partition a database into smaller, more manageable pieces called shards. Each shard holds a subset of the overall data, allowing the system to distribute load and storage across multiple servers. This increases performance and scalability by reducing the amount of data each server has to handle during queries and transactions. If you are performing or planning to do database sharding, fucking stop right fucking now. For real. If you are at that point where this is even entering your mind, or conversations you are involved in, you have lost the plot (like I said, it's a trigger for me). Either you are on-prem (in which case you're already literally more than a decade behind, and no, I don't want to hear your bullshit about security or privacy, both of which are ridiculous talking points), or you are choosing not to use the many, many, many existing solutions to an outdated problem.Even if you can't see past using a RDBMS for all sorts of reasons (mostly, they all roll up to "we're used to this", and I actually understand that reasoning, especially if you have an existing staff who know their existing world well and are unlikely to evolve), the cloud providers have abstracted these problems away. AWS RDS boasts that they "automate the undifferentiated database management tasks, such as provisioning, configuring, backups, and patching" and further manage "scale with demand." They've further made inroads to manage the movement of data into and out of your data swamp (on S3). In short, this allows you to remain rigid with your existing technologies but avoid sharding almost entirely. Now, if you are someone who falls into the exception ("almost entirely") than perhaps it is time to explore any of the other options (such as S3 and Presto/Trino/Athena). That's certainly not the majority of you (and it's nobody in New Zealand and the vast minority of companies globally), but that also is not to say there aren't other incentives to moving away from your RDBMS, which I will talk briefly about here. To be clear: I'm absolutely not saying that nobody in New Zealand should use the likes of (e.g.) Athena. I'm saying that nobody in New Zealand has such huge volumes that they are forced to use (e.g.) Athena. The distinction is important; I love Presto/Athena and still choose to use it.
About 5,000 words ago, I said that "[historic concepts and driving factors] are part of the history that has driven how we build things now." Speaking about RDBMS technologies here brings me back to that. If we think about still-existing architectures like LAMP, a RDBMS is part of the bundle. And that's not limited to PHP solutions; anything from Java to Typescript to Ruby to what-have-you can be used to build out products that are backed by a RDBMS. So what's the problem? Well, remember what drove our data models on RDBMS? The desire to minimise the number of copies of data that are written to disk, largely because of historic cost drivers, and to abstract the text using integer values (which compress better). This led to the relational model, etc. These relational models continue to exist, and we have volumes and volumes of books, university classes, and combined centuries of experience building and deploying these things.
So what's the rub? Well, let's just keep this really simple and say we have a web application that is backed by a RDBMS that uses a relational model. Now, when a query or user interaction occurs (e.g. get_purchases()), that initiates a query that has to retrieve data from (potentially) multiple tables. Perhaps it has to join CUSTOMER to PURCHASES to CART. Traversing those joins has a cost in terms of performance. And this is a very simple illustration; often traversing the model is far, far more involved! And that performance cost can add up. Think I'm exaggerating? Well, Amazon found that every 100 milliseconds of latency cost them 1% in sales. The article goes on to say that [a] broker could lose $4 million in revenues per millisecond if their electronic trading platform is 5 milliseconds behind the competition. 5 milliseconds! So performance freakin' matters. And because we've built performance hurdles into the foundation of the what (RDBMS) and how (relational models) of the entire backbone of our simple web application, now we have to employ techniques to fix that. What are they? First, they're indices on the RDBMS. Enter the DBA. The "D" stands for Database, not Dickhead, but with many DBAs both apply, but I digress.
Vitally, because we know the queries that are coming from the frontend, like the get_purchases() functionality, we can optimise those joins via an index, and oftentimes, we can (for some overhead of the index itself) help the performance of traversing the tables. Not solve it, but make it better. And then when that isn't enough, we do the next logical thing: a cache layer. We put the data that is most often needed, and/or most recently retrieved, and we put it into a memory layer that sits between our get_purchases() and the backend RDBMS. Memory is obviously a lot faster than reading off disk, and this is faster than the index, so we make further strides to offset the known performance issues that are inherent to the technologies and patterns that we chose to use in the first place! And we used these optimisation techniques BECAUSE WE KNEW THE QUERY PATTERNS!
NoSQL came along and rightfully said "this is ridiculous. Why are we using RDBMS in the first place when we know the query patterns? Why not use technologies that allow you to retrieve the exact data you need when you have the knowledge that you do? Why join different tables at all? Why do we need these indices? Why do we need this cache layer at all?", and NoSQL was right. This isn't to say that a cache isn't sometimes still required, but it's massively more infrequent, especially if the NoSQL technology is modern and the model you're using is correct. This isn't the right post for this, but I'd be remiss if I didn't at least explain that this is why I prefer backend-for-frontend, single-table-design DynamoDB.
Backend-for-Frontend (BFF) is a design pattern where a dedicated backend is built to cater to the specific needs of different frontend clients, such as web, mobile, or desktop applications. You know...shit where you know the query pattern. Instead of using a single, generalized API for all clients, the BFF pattern creates separate backends that are tailored for each frontend, optimizing data flow, reducing over-fetching or under-fetching of data, and simplifying frontend logic. For example, in a mobile app, the BFF might aggregate multiple API calls into one response to minimize network calls, whereas the web BFF might prioritize faster response times with more granular control. This approach also isolates frontend-specific logic, keeping the system modular and easier to maintain.
In DynamoDB, the Single-Table Design refers to the practice of storing all related entities in a single table, using a combination of partition keys and sort keys to model relationships and efficiently query data. This is a shift from traditional relational database designs where separate tables are used for each entity. In DynamoDB, single-table design leverages the flexibility of schema-less data and the power of primary keys to handle complex access patterns with fewer queries. It reduces the need for expensive joins and allows the database to scale horizontally more effectively. However, it requires careful upfront design to ensure that the access patterns are optimized for performance, as inefficient use of partition keys can lead to hot partitions and degraded performance.
This is an aside to call out that I am not a proponent of RDBMS being positioned as the backend for a product. But that doesn't mean that I am not a proponent of RDBMS, or at least the concepts behind it (and in particular, relational models for analytics). So let's give equal air time to that. Where does RDBMS thrive? RDBMS excels in environments where data exploration is crucial, especially when you don’t know all the questions you need to ask upfront, like in analytics or business intelligence scenarios. So, where you don't know the queries, which is very different than when we add a button to our product that says "add to cart." RDBMS offer powerful querying capabilities through SQL, enabling ad hoc queries that can uncover insights from complex, structured data relationships. The structured schema design enforces data integrity and consistency, making it easier to explore relationships between different datasets and generate insights on the fly. Features like joins, aggregations, and indexing allow analysts to dynamically filter, sort, and manipulate data across multiple dimensions without predefined access patterns. This flexibility is particularly valuable in exploratory scenarios, where the ability to iteratively refine questions and queries is essential for discovering trends, patterns, and insights in the data.
So I like relational models, whether they use RDBMS (e.g. Postgres) or whether we're creating a DBMS abstraction (e.g. Athena), when they're positioned correctly and we don't necessarily know the query patterns up front. One quick note: sometimes we do. A dashboard that retrieves (e.g.) revenue by quarter knows the query pattern. It still counts here because it relies on the underlying data in the relational (star schema) data model, but we can add an index, if necessary, in a RDBMS to improve that dashboards performance.
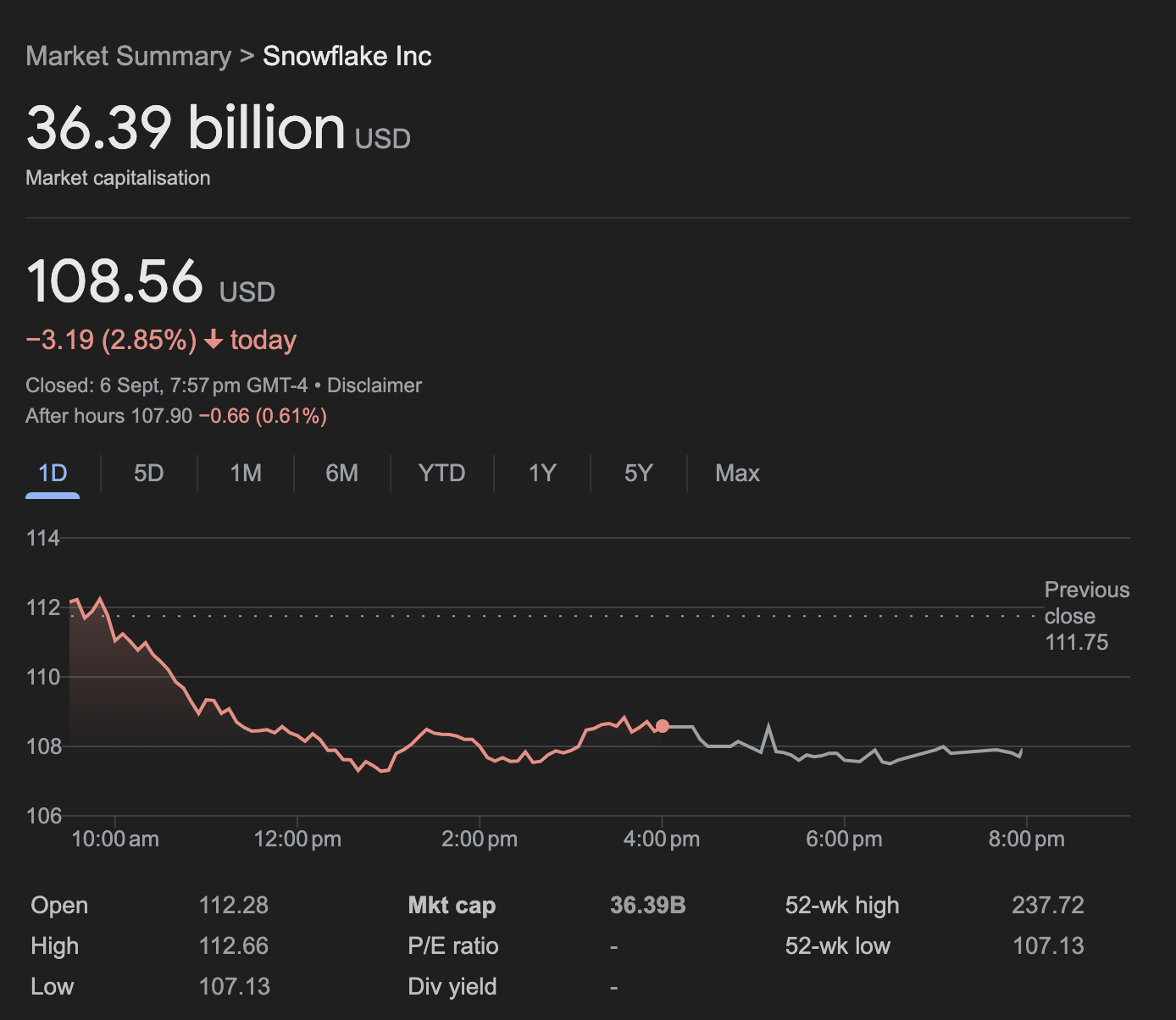
I was reminiscing earlier about the company I had before moving to New Zealand, and I had said that we helped design and implement "infinitely scalable" modern data platforms as a professional services offering. In particular, that focused on decoupled compute and storage, and being able to optimise each of them, independently. Really, it was a roll-your-own version of what the likes of Databricks and Snowflake now offer for a premium, and lacked the polish and refinement that comes from having massive staffs (Snowflake, at the time of this writing has a market cap of more than $36 billion USD. It stands to reason it was a bit more refined than the handful of us were able to do!). So I introduced these same concepts and expected that we'd (of course!) want to make sure that things were scalable and that we were exploiting the pricing model of the cloud.
What I didn't appreciate was just how small the data here actually was. For everyone. Even if we were a bank, and we had every single Kiwi using it (approximately 5.2 million), and every single Kiwi made ten (!) transactions per day, in one year, that's still under 19 billion transactions (18,980,000,000). Guess what? That doesn't come close to meeting the requirements of the definition of Big Data! And no bank has all the Kiwis. And all Kiwis don't make ten transactions per day. In fact, very few would. I'm using a ridiculous and extreme example, and even my extreme and ridiculous attempt to create volume still doesn't qualify.
Now, I want to be crystal clear about this point: I am absolutely not advocating for RDBMS. I have strong feelings about positioning the relational model correctly, and I do advocate for getting that right. But I am not condoning the use of RDBMS because I always promote the use of the cloud, and RDBMS is not cloud native. It's historic technologies that tightly couples compute and storage, and often requires special vendor licensing (Microsoft, for instance, when it comes to SQL Server). I do absolutely recommend and support correctly positioned relational databases. What my point is, when it comes to understanding both how we got to where we are today and why is that even (and especially!) because we've embraced these big data technologies, we've gotten away from some of the fundamental patterns and approaches that made sense historically. And that has been a mistake.
With the benefit of the passage of time, and with an appreciation that if you're not Google, Facebook and Amazon, then you probably don't have big data, by definition (and, of course, that's not a exclusive list, but it's hyperbole intended to reinforce the idea), I am going to make an argument here for getting back to some of the fundamental things that we got away from while we transitioned from Data Warehousing to Big Data, with all the Data Lakes and Data Swamps and the fucking Data Lakehouses (this has to be the stupidest marketing bullshit that data has ever embraced, and that's saying something. Collectively, Data loves stupid marketing bullshit). While we were all focusing on these things, and all the side effects of it (Pig/Spark/Flink/YARN/Hadoop/Storm/Real-Time/Streaming/Micro-batch/etc.), we got away from our fundamentals. And in the process, we forgot that the most important thing is getting value out of our Data. ALL THE REST OF IT IS A MEANS TO THAT END. BUT WHEN THE MEANS BECOMES THE REAL FOCUS, THE ENDS NEVER COME.
Data is About the Results, Not the Processes to Get There
So I am making an appeal, and I'm willing to come to the table on this. Despite my not condoning RDBMS (because I don't like tight coupling, because I do like cloud-native, and because I do like exploiting the pricing model of the cloud), I'm not going to whine about that any more. I will speak to you, the reader who uses Postgres just like I'm talking to you, the reader who uses Redshift just like I'm talking to you, the reader who uses Databricks just like I'm talking to you, the reader who rolls their own, whether that be Athena or something else. Give a little, take a little.
It is my belief, from what I've perceived and observed, that the collective we have gotten so focused on the how that we've ignored the more important part of why. The point is not, for example, to debate the minutia of micro-batches measured by some number of milliseconds versus true stream processing. The point is to accomplish a thing. I don't necessarily care if an overnight batch process takes 30 minutes or 90 minutes, but I do care that the process is done in the morning before everyone comes into the office, and when they get there, that the data is accessible and accurate and trusted.
I have had so many conversations of late from Data folks in which their organisation has gone out its way to implement Kafka, with absolutely no technical reason to do so, beyond internet-level understanding or past experience. The latter of which might be valuable, but perhaps not at the cost of moving away from services that are actually native to the cloud provider you're using. To that end, if you want to debate Kafka and, say, AWS Kinesis, my argument for the former is that you have A LOT of data. I did a multi-year contract at Box, and we were processing a handful of petabytes per day, and we needed Kafka, but given other scenarios, I'll almost always choose Kinesis, because it's a native service within AWS. So, while it might not quite process the same volumes, they more than comfortably process your volumes, both now and forever (speaking to the 99% of the world), and vitally, Kinesis integrates with the rest of the AWS services. That's a massive benefit! Yes, I do understand that AWS has launched MKS has been launched, and oh hell no, that doesn't change anything. At all. Just because the provider has grudgingly offered some wrapper over the top of a technology does not make it a native service. And if you've worked with AWS for any period of time, you should know by now just how shitty things can go when they do this (see Glue. For god's sake, see the ridiculous mess that has been ElasticSearch). So when you sign up for MKS because Kafka gives you a tingle in your happy parts, take a cold shower and then make a better decision. What I'm trying to say here is that we should be simplifying our systems, not embracing the wrong technologies to solve problems that don't actually exist. Again, not saying that the likes of Kafka aren't impressive and fantastic in their own right (they are amazing technologies), but rather that they're all-too-often solving problems that don't exist, and the trade-off of those choices (like breaking from the AWS ecosystem and in turn, giving away the out-of-the-box integrations that come with it) far outweighs any remaining benefits. And please, for the love of all things holy, don't say you are doing it to be cloud agnostic.
I've also been subjected of late to insanity around leveraging DynamoDB and other NoSQL technologies as an analytics environment. Do not do this. For all the reasons, don't.
So I'm hearing all of these things about Data Lakes (Swamps) and Lakehouses (come on now, this is getting ridiculous) and using technologies built for scale that will never come at the costs of a lack of natural integrations to native-to-the-cloud-provider (versus managed-by-the-cloud-provider) and other complexities that accompany it. Making decisions to go outside the cloud provider should be carefully thought through. It doesn't mean you shouldn't at times do it, but appreciate the downsides of making that decision, and the exponential impact it has doing it again. And again. And again. Slippery slope. Another one is using NoSQL as if it's a relational database. And I've had way too many discussions about the Small Files Problem and debates between ORC, Parquet and Avro, again for volumes that aren't going to appreciate the differences. And again, these challenges very much do exist, but how about we solve for problems that exist instead of creating our own along the way and losing the right focus. The decision to use Spark, again, for data volumes that aren't justifying it and without streaming requirements or anything close to it is an approach I've taken in the past and one that I'd like to get back, when the volumes didn't really justify the challenges of it. Again, I like Spark. But I sure as shit would prefer not to have to use it, all things being equal, and what makes my eyebrow twitch is when I see that as the choice being made without the understanding of why, and then losing themselves in the day-to-day minutia of that technology. If you know what these things are:
conf/spark-defaults.conf.template
conf/ log4j.properties.template
conf/spark-env.sh.template
Then you should be able to justify it with data volumes or streaming requirements. If you can't, perhaps you're guilty of losing focus. And if you use Spark and don't know what each of those things are for, then should you be using the technology in the first place, or would you perhaps benefit from simplifying the tools in your toolbox? The focus needs to be on the solutions and the outputs and the value, not how we got there, resumes be damned.
Again, I've made these mistakes myself. And I prefer ETL to ELT. And I prefer Python to SQL. And I want the data processing and data integration to happen outside the database, for all the right reasons...but I also appreciate that I made certain decisions because of those strongly held convictions that ultimately led to complexities that weren't necessary, and environments that shifted the focus away from the data outputs in favour of the data integrations. I chose the wrong horse for certain races, either because the track wasn't right or because the jockeys weren't. Oops.

Let's get back to the basics, starting with the skills that that everyone on your Data staff should have, in spades. Ask your Data Engineer to explain an advanced dimensional model. Give them a business situation and have them model it, and you should be able to make sense of how you'd get answers from it (without help). Ask them how to write SQL to traverse a network (like people in an organisation). Ask them how to find the median using SQL, and why you'd want to. Ask them why you'd ever use a pie chart, and if they have an answer other than "you shouldn't", take a deep breath and try not to scream. The point of your Data environment, and by extension, your Data staff, should be about leveraging data to provide insights and value to your organisation. If there is staff who either can't answer simple questions like this, or who don't think that should be their responsibility, then staff has lost their way. It's not their fault. They probably don't know any better, but this culture is also to blame for why we seem to need larger and larger staffs and budgets for your Analytics stack than we do for any other department of your technology ecosystem. We have lost our way. And our Data environments are suffering. In turn, our products and our businesses are suffering. The promise of data is becoming an empty one.
Get back to the basics. Appreciate that you don't have to reinvent every wheel anymore. In fact, traditional technologies have caught up for probably more than 90% of all use cases outside of Silicon Valley (and maybe even in it), so if you really want to focus on the goals and promises of data instead of learning all the painful lessons associated with the explosion of volumes over the past fifteen(ish) years, you have permission to use traditional technologies, and please, use traditional patterns, because they still work, even if they've been ignored for years.
Build a data model that is disciplined and well documented. A disciplined data model is an accessible data model, and an accessible data model encourages and empowers self-serve. That in turn saves you money in staff, and creates a level of trust and engagement in your Data environment. Let the users become to the advocates, and the creators of a flywheel of value and opportunity. With each spin of that wheel, more value is created, and more opportunities arise. It will ignite things around machine learning. And now, it will do the same for AI.
AI - How Does it Fit?
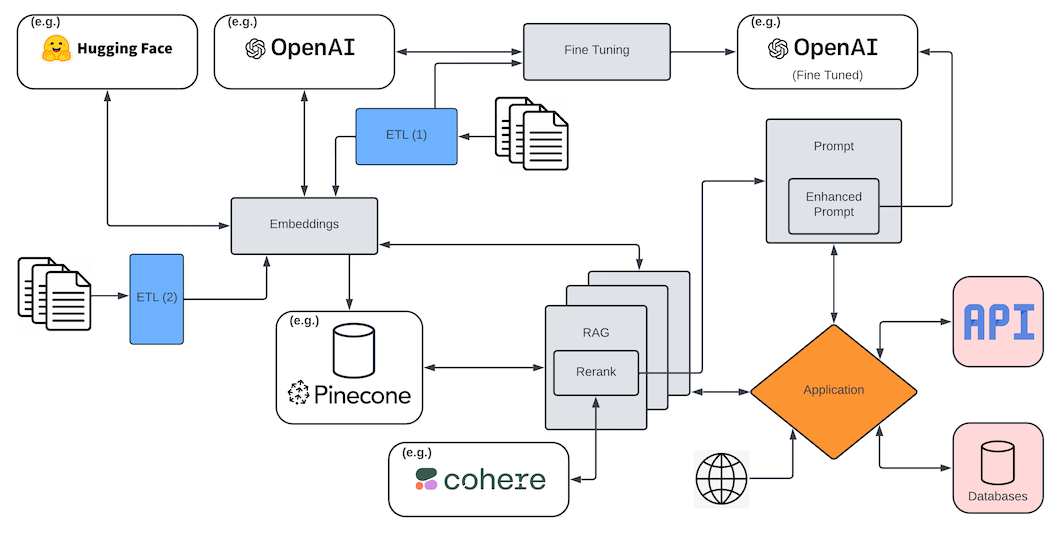
I have hand waved over a number of things here, but one that I will spend a bit of time on is AI. For most people, AI at this early stage is little more the likes of ChatGPT. For many LLMs, data is just the corpus of information that a large language model is trained on. And as I have said for nearly two years now, you're not building a LLM. That's a game that Microsoft/OpenAI and Amazon and Google and similar play. Unless you're them, you're not building a LLM. You might be tuning one, but that's very different. And more realistically, in a year or so, you're going to want to implement either a multi-agent system that accesses your data environment (via API or other means) or a RAG implementation that has an important data element to it, whether that be a vector database or a graph database, or some other backend that you use to access data that is ultimately going to be passed into a prompt alongside a query.
And this is incredibly important! It's seriously going to be bigger (in a different way) than the internet was, because it enables so many human tasks to be done by the machines with limited (and unstructured) inputs. Obviously, it's a lot more complex than that, and that's a ridiculously over-simplification and massive generalisation, but it's enough for now, at least for this discussion. In fact, continuing with that some basic generalisations, I'm going to split AI data into three parts, as it pertains to the topic of this post, and I'll go a step further and break out the Data & Analytics aspects as they pertain to AI. The point of what follows here should be that if your Data platform isn't already doing the needful to accomodate AI, then your Data platform is quickly falling behind. Elegance is found in simplicity. Get back to simplicity with your Data environment so you can have the capacity for things like AI, not seemingly endless cycles managing unnecessary complexity.
The AI Data itself
First, there is raw data that is going to be used to tune a model. Not train it...tune it. I always rant about this, so I'm resisting doing it here. There are different techniques to tuning a model, including but not limited to creating questions/answers and layering that on top of a trained LLM. This source data is unstructured and/or semi-structured, then cleansed and put into whatever tuning format is needed for the approach being taken. This is data that doesn't reside in the dimensional data model, and has little to no analytic value. You'd probably use the same service as you do for the Data Swamp, such as S3, organising it between "raw" and "cleansed", or similar.
Secondly, you have data that is in some form that is semi-structured, rather than purely unstructured. While these data types do not fit into conventional databases like structured data (e.g., rows and columns in relational databases), they often contain an inherent structures. Perhaps these are images, videos, or PDFs, to name a few. As they pertain to AI, these might be objects that I'm going to persist in a vector database, for instance, for use in RAG pipelines. This data is also unlikely to be stored in a relational database, except perhaps as metadata, whereas we're cataloguing the data and recording the location of it outside the database (using the term "database" correctly here as "a structured set of data held in a computer, especially one that is accessible in various ways", not as a RDBMS). Instead, the data is, like its unstructured brethren, in a "raw" area in S3, for instance. Those data must be translated into embeddings, or a series of coordinates of various lengths (depending on the index configuration and proximity algorithm used), and those embeddings that represent the semi-structured data lend itself to either (or both) S3 and a NoSQL database, such as DynamoDB, if desired.
Finally, you have interactions and results. These include prompts and historical queries and responses. These can be used for certain analytic purposes, such as sentiment analysis and further tuning of models, to name a couple, but isn't used for things like reporting. This data is very important and steps should be taken to assure it is persisted in as pristine a manner as possible, since it can necessary to do things like load historic conversations, and feed LLMs to provide back-context to ongoing querying. That said, there are often other things that may need to be done to this data, such as using a LLM to summarise older parts. This in turn requires capturing the relationship between the raw conversation and summarised aspects of it. It can be persisted similarly to parent-child relationships, or using other techniques.
The other thing I'll call out is that modern data platforms used to be about the three V's: velocity, variety, and volume. Now, that's little more than table scraps and just a baseline by today's standards. I see the variety today being more disparate technologies and platforms to comprise your data environment. Now, it's the disk that houses your Data Lake, unstructured AI data, and semi-structured AI data, along with the various incarnations that stemmed from them. And it's the relational model that we've unfortunately gotten away from, and in the void left, confusion and a complete lack of self-serve capabilities emerged (despite plenty of ongoing lip service to the contrary on the latter). And for AI, it's data we're accumulating and curating for tuning. And for RAG, it's a vector database, for sure (with various uses, ranging from semantic searches to proximity calculations on images, to name a couple), and it's potentially graph databases for network retrieval in AI, to pass to prompts, and maybe even something from the Lucene world of technologies. And finally, it's a series of API endpoints and access to structured data for the same.
All right, this isn't supposed to be a post about AI, but I think it's important to talk about this, and I'll probably dedicate a post to it in the future, because I feel like I have 10,000 words to say about that, too, but I'll wrap these 10,000 words up first!
The point of all of this (finally!!!) is we've lost the foundational and fundamental skills of data modeling, as part of the fallout from volume, the fact that disk has gotten so cheap, and the cloud has provided an excuse to simply throw more and more compute at the problem. By definition, almost nobody has "big data" anymore. Traditional technologies and tools can accomodate your needs, but even if you do choose to leverage cloud-native solutions (like I do), you can and should still have a disciplined data model, because that's ultimately what creates self-serve Analytics. And it ultimately means less staff, and higher trust in the Data. And as part of that, we should be able demand that our Data Engineers and Data staff has the requisite skills to call themselves Data experts.
So if you can justify it, and you deeply understand the fundamentals, and you deeply understand the technologies you're using then by all means go the Presto/Athena route. Go the Kafka route. Decouple your compute and storage. And if you have deep pockets, go with 3rd party platforms and architectural patterns that have understood flaws, if that's what you want to do. But make sure you don't ignore the data model. Just make sure you really understand the fundamentals first before you start to convince yourself that "big data" technologies are what you need, or that they'll somehow fix everything. They won't. Think of Data the same way you would your home, with the fundamentals and patterns of data - the ones that date back decades and decades - are the foundation, and if that isn't strong, nothing you build on top of it can be, either.
It cannot continue to be acceptable to have people on your staff who identify as Experts and Seniors who haven't done their due diligence in gaining those skills and exhibiting some level of career capital applying the foundational concepts that continue to underpin Data environments. This goes beyond basic SQL skills, and includes data modeling, data visualisation, statistical analytics, (minimally) an understanding of machine learning (basic models, like KNN, linear regression, and random forests), and an understanding for how to build and deploy a model, and now, AI (fine-tuning, RAG, and prompt engineering, along with an understanding of how to build a Data environment that accommodates each of them). Yeah, this is a bit of a "back in my day..." rant, but from my vantage point, these past few years, (generally, of course, I don't know your particular situation) what we've been doing is lowering the bar and confusing the landscape by focusing on solved problems and complexities of our own creation, and in the process, we've lost the plot. It's time to get back to the fundamentals and make Data the "new oil" that it promised to be.
As always, thank you for reading this nonsense.