Joel
JoelDisclosure: All opinions expressed in this article are my own, and represent no one but myself and not those of my current or any previous employers.
Anyone paying attention will surely attest to the speed at which generative AI is moving. For many (most?) folks, generative AI is still largely synonymous with ChatGPT, and without a doubt, OpenAI (the company behind it) largely has been, and continues to be, the face of the movement. So I use that particular organisation to create a bit of a timeline to illustrate just how fast things have gone.
ChatGPT was released in November 2020, based on the GPT-3 architecture. GPT-3 was released in June of the same year, and it marked a quantum leap in AI capabilities, with 175 billion parameters. While understandably hand waving over a number of significant releases and enhancements across generative AI, and fast forwarding to May, 2024, GPT-4o was released. That model can reason across audio, vision, and text in real time. GPT-5 is expected to be launched around the end of this year, or early next, and there are already rumours that it may be multi-modal, more personalised, and potentially combining the likes of text, images, audio, and video. To put a technical lens on it: shit be moving fast.
I know it's not all about the tokens, but it is worth noting just how much more these newer models are trained on. While the exact numbers differ across the interwebs, we can be generally correct enough for this discussion by using pretty much any of the numbers we're seeing.
GPT-2 was trained on ~10 billion tokens, whereas GPT-3 was trained on ~500 billion tokens. GPT-4 was trained on ~13 trillion tokens.
That is just mind boggling. In fact, it's practically impossible to even wrap our heads around that. This time, I will use a time analogy can help. Let's pretend that tokens are seconds.
def seconds_to_years(seconds):
# Considering leap years, we use 365.25 days in a year
seconds_in_a_year = 60 * 60 * 24 * 365.25
years = seconds / seconds_in_a_year
return years
GPT-2 was trained on ~10 billion seconds. Or, put another way, about 316 years. So, GPT-2 puts us back to around 1700, when the Transatlantic Slave Trade was at its height and William III had just died (or was about to: 1702) and Isaac Newton's "Philosophiæ Naturalis Principia Mathematica," published in 1687, influencing scientific thought profoundly.

GPT-3 was trained on ~500 billion seconds. Or, put another way about, 15,844 years. So, back when humans were essentially hunter-gatherer societies, carving and painting caves, and starting to create weapons out of stone.

GPT-4 was trained on ~13 trillion seconds. Or, put another way about, 411,945 years. That puts us back to the ice age! Homo heidelbergensis was a species believed to have been prevalent around 400,000 years ago. Homo heidelbergensis is considered a common ancestor of both modern humans (Homo sapiens) and Neanderthals (Homo neanderthalensis) were wandering the earth, apparently making snow-people.

Moving on...
Facial Recognition
I've mentioned to a few folks, and even potentially mentioned it in these posts from time to time, that I've been getting really into the intersection of computer vision and generative AI. This interest goes back awhile. In fact, we went to Europe for Christmas/New Years back in 2016, just a month after AWS released Rekognition. Rekognition is a service that allows you to do facial recognition, which I was (am) fascinated with. On the plane ride from America to Europe, I was able to create a basic system that could identify me and various members of my family, as well as Kevin Spacey and Robin Wright. To my defence, House of Cards was huge at the time, and we didn't know that Kev was rapey.
After I returned home, I put this framework to use, building out a "magic mirror" using a Raspberry Pi with camera, a two way mirror, and a flat monitor. Essentially, when I walked up to the mirror, the camera would take a photo (activated by a motion detector), initiate a Lambda function in AWS which called Rekognition via boto3, and returned information that I would be interested in. For example, it would comment on my unparalleled good looks (*cough cough* this may have been hard coded in), retrieve my calendar for the day, and subscribe to various RSS feeds of interest, like the Minnesota Vikings and AWS announcements. That information would be returned to the monitor which was visible behind the two way mirror. When either of my kids or partner would use it, they would enjoy similar customisations. When anyone the camera couldn't identify would be on it, it made some snarky comments and offered up jokes, etc.
It was a novelty. We hung it in the basement where we had the big screen TV. It elicited a bit of "wow" response from folks when they saw it, and a "man, that's creepy" (or similar) follow-up. My partner felt the same way. It was eventually banished to the attic.
RAG
I mention this because that interest in computer vision didn't go away after that, and over the past couple of years has found a new focus with the coming of age of AI. One pet peeve of mine is that while the AI wave has been incredible, the outputs have, too often, just been glorified chat bots. One thing that has been really interesting to me is how we can leverage the AI's capability to reason as opposed to just generating-the-next-word responses via annoying website bots.
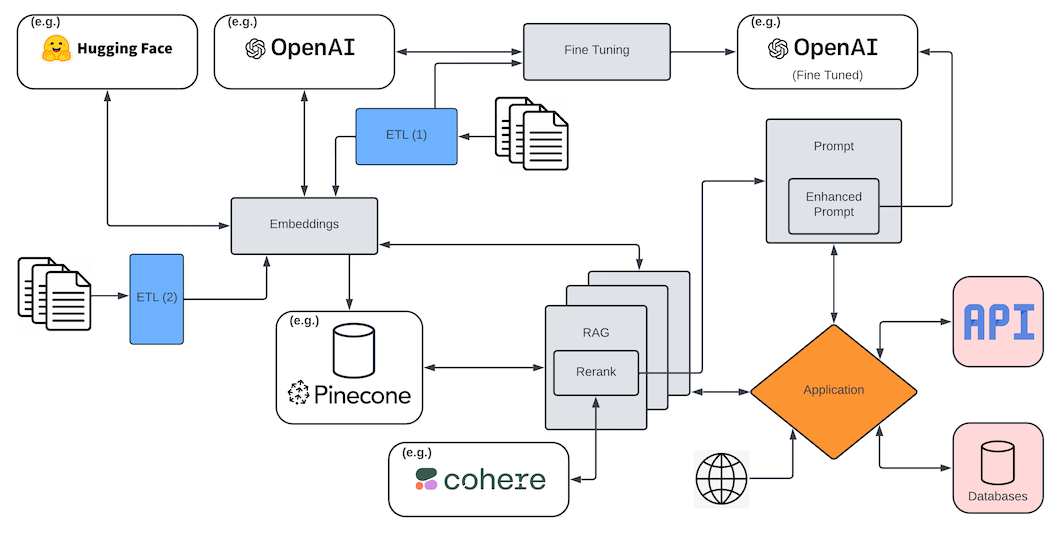
So I took this idea of computer vision and the capabilities of RAG, which I won't go into too much detail about here, since I have covered it again and again of late, beyond giving just enough context for those lucky readers who haven't wasted precious time on my other meandering posts:
RAG, or Retrieval-Augmented Generation, is a technique in natural language processing that combines the strengths of retrieval-based models and generation-based models. In this approach, a retrieval model first fetches relevant documents or information from a large corpus based on a given query (often, from a vector database). Then, a generation model, such as a transformer-based neural network (e.g., GPT-4o), uses the retrieved information to generate a more accurate and contextually relevant response. This hybrid method enhances the performance of language models, particularly in tasks requiring extensive knowledge or detailed responses, by leveraging the vast information available in external databases and the generative capabilities of modern AI models.
This is important because LLMs (generation models, in my above definition) tend to suffer from hallucinations and too general a corpus of training data to be effective. The quote below sums it up better than I do:
RAG endows the base models with enterprise-specific “memory” via a vector database like Pinecone. This technique is far outpacing other customization techniques like fine-tuning, low-rank adaptation, or adapters in production today, which primarily work at the model layer as opposed to the data layer.
Increasingly, I find myself needing to mention reranking whenever I mention or hear about RAG pipelines, because RAG in and of itself is rarely enough, beyond perhaps simple categorisation/classification examples. In nearly every case, some level of reranking is required.
Reranking in the context of RAG refers to the process of refining and prioritizing the retrieved documents or passages before they are used to generate the final response. In a typical RAG system, a query is first used to retrieve a set of relevant documents from a large corpus. However, the initial retrieval step may not always return the most relevant or high-quality documents at the top of the list. Reranking aims to address this by applying a secondary evaluation to the retrieved documents, using more sophisticated algorithms or models to reorder them based on their relevance to the query. This ensures that the most pertinent information is given higher priority, leading to more accurate and contextually appropriate responses in the generation phase.
The reranking process can employ various techniques, such as leveraging additional machine learning models that consider the semantic similarity between the query and the documents, the context within the documents, and other features like document length or metadata. By reranking the initial set of retrieved documents, the RAG system enhances the quality of the input provided to the generative model, ultimately improving the coherence, relevance, and factual accuracy of the generated responses.
Images
So, I started to take images and convert them to vectors, or numerical representations of the image, and then persisted those in a vector database. From there, I could take any other image and find similars. In that way, I could start to (amongst other things) categorise what was in the image without any machine learning. So, if I uploaded an image of a car, it would return other cars, and if I uploaded an image of a dog, it would return other dogs. I'm hand waving here for simplicity (it's not quite that straightforward), but you get the point.
And that was surprisingly powerful, beyond just the "is it a car or is it a dog?" example. Without giving away too much of the commercial angle I was pursuing, you can start to imagine a lot of information that was previously required from a user to input could suddenly be automated simply by having other images stored in a vector database. You could, for instance, create more robust inventory systems, or "find similars" functionalities without ever having to write a line of code to identify what constitutes a similar.
PDFs and OCR
Additionally and completely unrelated, I offered some of my free time to a gentleman I met in the area who is doing some interesting work at the intersection of AI and OCR. I've got a fair bit of experience with a particular OCR that AWS offers as a service (Textract).
Optical Character Recognition (OCR) is a technology that enables the conversion of different types of documents, such as scanned paper documents, PDFs, or images captured by a digital camera, into editable and searchable data. OCR works by analyzing the shapes and patterns of the characters in the image and then converting them into a machine-readable text format. This process involves several steps, including image preprocessing, text detection, character recognition, and post-processing to correct errors and improve accuracy.
Taking some of these same concepts but applying them to PDFs, using OCR, I was working on taking in the document, applying Textract to it, then vectorising that and performing proximity searches against the text located in those documents. Nothing too magical here, but an emerging pattern that is applicable to a number of different use cases.
Images
But then, in a matter of months, AI started to leverage images similarly to how they had text. So, now I could upload an image and have the AI reason as to what the image contains. This was truly disruptive. Now, I could take an image, create a vector and persist it (see above) and that would allow me to retrieve similar images using basic RAG implementations. But in addition to that, I could use AI to generate information about the image itself (which produces text output) and I could leverage an embedding model to vectorise that text and store that in a separate index.
From there, it was a short leap leveraging the semantic proximity of the vector database to do even more interesting things. As I have said elsewhere:
Being able to derive semantic meaning and relationships between data points in a high-dimensional vector space is superior to Lucene indexes and simple keyword matches because it captures the nuances of language and context more effectively. Lucene indexes and keyword matches rely primarily on exact word matches or predefined rules, whereas vector representations encode semantic similarities and differences between words and documents based on their context and usage. So I could use these little sweethearts to allow for more nuanced understanding of similarity and relevance, even if they don't share exact keywords or phrases.
So now I could take the AI generated information about the image itself, create a vector based on an embedding model, and store that in a separate index in the vector database. For those scoring at home, we've now got the "proximity index" (if you will) in the vector database that returns similar items, and a second index that is capturing the textual descriptions of those images, which allow me to do semantic searches. You can probably see where I'm headed here.
Now, I can take other text and perform semantic similarity searches to find images that might satisfy my query. In my ridiculous illustration-only example above, I could enter in "a scarlet compact car from the 1970s known for its unique hatchback design. This small, vibrant vehicle was infamous for its safety issues during its production years" , convert that to a vector using the same embedding model as I used on the text returned from the AI generated image metadata, and return a red Ford Pinto. And if I've done things right, the key of that text uses the same UUID key as the image (or contains it in the metadata), thereby enabling me to return this image for that text entry:

This can become really powerful because now I can start to generate predictions in a new way, just by doing semantic proximity searches against the text that was generated from an image.

All right, maybe that isn't mind blowing for everyone, but for me and my little brain, it kinda was! And to be clear, I'm not advocating for this to somehow replace predictive analytics or machine learning algorithms for recommendation systems. I sure as shit hope not, since I've spent a number of years earning certifications and accumulating career capital in those areas! But, I think it is really powerful, I think it is but one of many use cases for this, and it becomes yet another tool in the toolkit for organisations and practitioners alike.
So, now I had this interesting capability built in which I could not only generate a wealth of information about an image, but I could also generate recommendations against that wealth of information, including the ability to leverage similars and semantic similarities across different vector database indexes.
Audio
From there, I incorporated the audio capabilities that GPT4o also offered. I won't go into too much detail here because it's pretty straightforward: I was simply converting the text of the AI generation to audio. But I do mention it because, like facial recognition and OCR capabilities, the AI itself was (is) making massive inroads. With the text-to-audio capabilities, the AWS service Polly became (at least somewhat) obsolete. And that's a big point to be made here: these specialisation applications still (usually) do a better job that a multi-purpose LLM, but if the past two years are any indication, that may not always be the case. And more importantly, they needn't be thought of exclusively. Similarly to how I was using the OCR in addition to a RAG pipeline and in addition to the visual capabilities of AI, it more accurately becomes an additional layer and additional input that can be used together in order to get even better outputs.
I think about that like this: if the output of a RAG pipeline is to obtain additional context that can be passed to a LLM (or a "generation-based model", if you will) in order for it to generate better results, then layering in the output of a OCR in addition to what AI might have reasoned as being on that PDF should result in better results - especially if we incorporate multi-agents! In that scenario, we could hand the output of the OCR to one agent and the raw image to another (noting a PDF to image translation is required at the time of this writing, which is pretty trivial), and have each independently generate a response, and in turn hand those to a third (coordinator) agent who in turn could use both to create the ultimate response or continue to iterate with the other agents until the response is satisfactory.
But we're not done yet, though I promise we're getting there.
I haven't talked about video yet.
Video
I've talked a bit elsewhere about a personal project I worked on that generated unique content, in the form of a blog, about the Minnesota Vikings, who happen to be my favourite cause of high blood pressure and depression. Again, for the lucky reader who hasn't found that post discussing that yet, here's the first blog it generated:
Listen up, you're about to get the real lowdown on the Minnesota Vikings. Everybody wants to talk about the glitzy quarterbacks and sexy edge rushers, but underneath the hood, there’s always something simmering we oughta focus on. So, buckle up because we're taking a dive into the deep, controversial waters of Vikings football.The football world collectively held its breath when JJ McCarthy, the Vikings' top first-round selection, started warming up. And why not? He's the new kid on the block who's supposed to bring the franchise back to glory, and everyone's hung up on every one of his handoffs and dropbacks. Look, you can hyperventilate over McCarthy all you want, but let’s give Dallas Turner his due. This isn't just another pick. The Vikings moved heaven and earth, surrendering more draft capital than a Wall Street firm during a tech bust, to snag this guy. Seven picks, folks. The Vikings have bet the farm on Turner, and anyone who's not paying attention better catch up quick.Let’s break it down—Turner has the kind of freakish athleticism that makes scouts drool. He’s the Swiss Army knife you need on a defense. Sure, he’s got too much energy and needs a metaphorical leash in practice, but isn't that what you want? Controlled chaos on the field? Brian Flores, who’s been around the NFL block, understands what he's got with Turner. Flores isn't just seeing another edge rusher; he's seeing a multi-positional terror, and let’s not forget the last time Flores got his hands on someone like this, he was coaching Dont'a Hightower to Super Bowl victories.Now, let’s talk about the price the Vikings paid. Draft capital, schmraphipal. Who needs it when you already hit the jackpot? The spreadsheet kings are wringing their hands about how the Vikings burned too many picks, losing future roster-building opportunities. Here's the kicker: Adofo-Mensah, the GM who did all this, says it’s part of a grand, all-in approach. Sure, the long-term stability might have taken a hit, but sometimes you have to throw caution to the wind and go for the kill. You play to win the game, right?Alright, so how does McCarthy feel about all this fanfare and noise? From his first 24 hours with the team, he’s throwing around names like Wayne Gretzky and downplaying any QB competition with Sam Darnold. In other words, the kid's cool as ice. Coach O'Connell is taking a slower approach; he’s not rushing him onto the field, not trying to ruin another promising young QB talent by throwing him to the wolves. The idea is to let him grow, learn the playbook, gel with Jefferson—the other JJ—and bring him into the spotlight when he’s ready. Hey, it worked for Patrick Mahomes, didn't it?Ultimately, the Vikings are gearing up for a rebirth. McCarthy and Turner are the new blood meant to reinvigorate a team that’s been teetering on the edge of greatness without quite getting there. If they manage to harness Turner's monstrous potential and give McCarthy enough runway to take off, the Vikings are not just going to be a team to watch—they’re going to be the team to beat. Get ready, NFL. The Purple People Eaters are on their way back.
Sticking with that theme, I then took a short video clip of a random Vikings play that I found on YouTube. From there, inline, I generated a series of individual images comprising that video clip. I then fed those images into AI and generated text describing the play. I then converted that text to audio. I then combined that audio over the top of the original video. The output was this (audio on!):
If you're thinking: "that isn't all that impressive", I would tend to agree. But worth noting: I didn't tell the AI it was the Vikings. Or that it was 2nd and goal, etc. And what is impressive, though, is that I was able to do it in under two hours, from a blank sheet to a video with AI generated audio. And if you know me, you know I ain't all that bright, so I'm crediting the accessibility of these technologies, not my own awesomeness.
And also worth noting, GPT-5 is expected to be released later this year or early next. And there are rumours that video will be part of the offering, out-of-the-box, which is to say that those couple of hours might be on the verge of getting shorter.
Going from where we were in early 2020, when "a chatbot named Replika advised the Italian journalist Candida Morvillo to commit murder" and scores of other problems existed using these "new" technologies to where we are today: in a couple of hours creating a PoC of what the future of sports announcing could be, without humans, is absolutely remarkable, and it makes me happy that I'm alive to see it. But without those technologies being accessible to the masses, in terms of the chips to build the LLMs, cloud providers that enable use of varying technologies to persist data and providing computation and various services to process against them, and frameworks like Hugging Face and LangChain to glue it all together, it's all for naught.
And that's the point I'm trying to make here: not only is the technology moving at speeds I've never seen before (this is the internet on steroids when it comes to just how quickly things are changing beneath and all around us). But the approachability and adoptability of those technologies are moving as fast or faster, and it's worth understanding, considering and appreciating that, because it's one of the big challenges I've been experiencing, and I know I'm not alone.
We're building software and writing code, and even in the most (lower case "a") agile of environments, by the time we're ready to release a piece of AI functionality into the world, there might be a dozen of ways of doing it differently, or better, or faster, or cheaper (or a combination). But, that's the game we, as AI Practitioners, are playing, because of the point in history that we find ourselves in and the state of the technology world.
There are plenty of opportunities to turn this into a larger discussion about how this is why being the second mover is advantageous, and how they don't pay the same pioneer tax that the first movers do. And as someone who was working in the AWS cloud back in/about 2010 (when it was not much more than EC2, EMR, SQS and S3), I can tell you that paying that tax takes a toll. But those services are still in play, whereas the ones we're working with today are changing out from underneath us in more wholesale ways, so as Mark Twain so elegantly said, while history doesn't repeat itself, it rhymes.
But I won't take this as one of those opportunities. Instead, I'll end it there.
Thanks for reading.