 Me
Metl;dr Relational databases are great, when they are positioned correctly in an overall architecture. RDBMS are (mostly) unnecessary. Always build for bi-directional scale, and always take advantage of the pricing model of the cloud.
In my previous post on Function as a Service (FaaS) architectures, I mentioned how I was taken not necessarily by what technology components comprise the architecture, but what wasn't there, including a RDBMS (Relational Database Management System), which is traditionally a mainstay in most technology and analytics systems. I want to discuss here the pros and cons of taking that approach.
First, let's be clear about one thing: we have databases. In fact, we have multiple databases, if we use the Oxford dictionary definition of a database, as:
“A structured set of data held in a computer, especially one that is accessible in various ways.”
What we don't have, however, is a RDBMS, which is basically a system to manage our database, or as Wikipedia defines it:
“Connolly and Begg define Database Management System (DBMS) as a "software system that enables users to define, create, maintain and control access to the database". RDBMS is an extension of that acronym that is sometimes used when the underlying database is relational.”
Traditional RDBMS include the likes of MySQL, Oracle, and DB2, to name just a few. Natively distributed RDBMS include (e.g.) AWS Redshift, and Snowflake. I say natively because many traditional RDBMS can now work in a distributed fashion, especially if we consider database sharding, but that's beyond the scope of this post.
Although less so today than in the past, many web applications continue to leverage the LAMP software stack, which is comprised of Linux, Apache, MySQL, and PHP. Using that stack, a RDBMS is clearly part of the core componentry. I personally feel that's an outdated approach for a handful of reasons, including:
- Scalability
- Costs
- Speed
- Coupling
The image here is a high-level look at a simple LAMP architecture, where the RDBMS is used for both the front-end as well as analytics, using Tableau as the data visualization application.

Speaking quickly to each of the items in the previous list, the reason I feel scalability and costs are problematic is in large part because of tight coupling. When our compute and our data storage are tightly coupled (as they are, co-located on the same server), we have to consider each in conjunction with one another. To illustrate: imagine we're storing a terabyte of data in our RDBMS-perhaps it houses all of our customer and address information, including all of their purchases and all history. We need a server that is large enough to contain all of that data, and that server is going to have a plethora of computational resources, too, whether we need it or not. The cost of disk is quickly approaching zero, but the cost of compute is definitely not; rather, compute continues to be costly as chips continue to get more powerful and smaller. In this instance, we're paying for compute when all we really need extra of is disk. This doesn't scale well. As our business continues to grow, we continue to need more and more disk, so we have to continue to buy bigger and bigger servers to meet those disk needs.
Alternatively, perhaps we address the above by keeping only the current information we need in the RDBMS. Perhaps we only need, say, current customer information and current address. We can easily segregate historic data to a disparate system for use in analytics (which historically is another RDBMS, which then has the same challenges and limitations). Now, we have a server that is "right-sized" for the data being housed in it, limited to the disk we require plus some additional overhead (for materialized views or various indices, perhaps), but now we're limited to the amount of compute that is available on that server. Now we have a new (and worse) problem on our hands: finite compute.
The image here extends the previous image, now with a separate RDBMS used for analytics and data science.

Imagine this scenario: we have our RDBMS server, which is right-sized for the amount of disk we require, and that server has enough computational resources (e.g. memory) to handle our daily load. But on Black Friday, our compute needs change because so many people want to buy our widgets. Now, our server can handle the customer information it is obtaining from a storage standpoint, but it can't handle the processing. What happens in that scenario is the server falls over, and we're unable to sell our popular widgets, and on our busiest day of the year!
This means that we have to have a server large enough to handle our peak traffic, even though 364 days a year we're wasting compute that sits idle.
Additionally, the speed of traversing a RDBMS is significantly slower than alternative technologies, such as a document datastore, like DynamoDB. DynamoDB is bi-directionally scalable, so additional resources can be added dynamically and seamlessly, and (per the aforementioned link) can “support peaks of more than 20 million requests per second”. The trick, however, is recognizing the cons of a document datastore; specifically that you need to understand the query patterns to retrieve data, and model your document datastore accordingly. That is the topic of a future post, but it highlights the main point I'm (finally) going to get to: relational database systems aren't going away, and nor should they. However, they need to be positioned properly in an overall architecture, and even then, you can have a relational database without an RDBMS.
The image below extends the previous image, now with a document datastore as a replacement for the front-end RDBMS and a separate RDBMS used for analytics and data science.

Before we delve into relational databases without RDBMS, let's talk about correctly positioning the RDBMS, and the benefits of these systems.
To be clear: I'm not anti-relational databases. Far from it; I spent the better part of two decades using relational databases, and RDBMS, writing ETL, building analytics and data visualization systems, and RDBMS are great for that. My points above specifically call out the downsides of the RDBMS within the LAMP architecture for a web application (I prefer a static site, javascript/jquery, and FaaS compute).
First, let's touch quickly on why relational databases are great. I'm a scale guy. My career has largely been about building scalable systems, and the last decade has mostly been doing so in the (AWS) cloud. In order for scale to be achieved, you have to embrace distributed systems, so it's worthwhile here to discuss some distributed RDBMS, such as Redshift, Teradata, and Snowflake, since many of their benefits/use-cases are the same as single-server RDBMS, such as:
- Data Visualization
- Data Exploration
- Analytics
The image here extends the previous image, now with a distributed RDBMS replacing the single-server RDBMS used for analytics and data science.

Most data visualization applications have grown beyond just RDBMS back-ends, but to be sure, they still prefer RDBMS backends, for obvious reasons: it's easy for the visualization application to do the types of things they need to do to produce the data for the visualization. Imagine we're building a data visualization to report sales by month, or sign-ons by geographic area, to name a couple. We have our data neatly put away in (albeit rigid) structures: our star schema data model. We can create a summarization of sales by month or sign-ons by geographic region by writing simple SQL statements, which is the native language for RDBMS. We could do this by accessing the data in a document datastore, but as was discussed previously, that structure is built for different types of data usage (specifically where we have a well understood access pattern). It would be incredibly inefficient to pull the data from a document datastore, parse the nested key/value pairs, and perform the aggregation or summarization. It would also be a red flag that we're not correctly positioning the document datastore, which is not optimized or designed for exploratory analysis.
Speaking of data exploration, this is a big reason we love relational databases. Our data model may be more rigid than the (oft-nested) key/value pairs of a document datastore, but that model is designed to do exploration, again, simply leveraging the extremely approachable SQL language. It is my opinion that every Data Scientist, Analyst and Data Visualization professional should have SQL as part of their toolkit. Using SQL and our relational database, we can join, group, and filter efficiently. If we're doing repeatable summarizations and aggregations, we can further optimize things by adding secondary indexes, without having to duplicate data, like you would in a document datastore.
So, I already talked about scalability, and why traditional RDBMS have issues in that area. Perhaps your data isn't so large as to have introduced challenges to storage (and the computational resources on that RDBMS sufficiently meets your requirements without excessive idleness). Perhaps you come from a traditional RDBMS shop (e.g. MySQL) and you simply want to migrate to a distributed RDBMS (like Redshift) to deal with scale. I encounter a lot of shops where the latter is the case. They say things like "we have existing SQL skills that we want to continue to leverage", or "we don't have the appetite to move to anything too different from what we already know", and these are valid reasons for making the decision of moving to a distributed RDBMS, or MPP system.
That said, I still issue the warning around tightly coupling your compute and storage, which is arguably now worse. Instead of having a single server that we're making storage and compute decisions on, we have a cluster of servers, and the problem can be exasperated, especially when the inevitable time comes when the cluster needs to be expanded, because we now also have to re-distribute the data across those new and existing nodes (servers).
The other thing people often fail to recognize is that while the physical data model is largely the same, applying a single-server star schema physical data model to a distributed RDBMS or MPP is absolutely the wrong approach to take. It will not meet your performance expectations, which we'll explore in some detail here.
In distributed systems, easily the most common performance challenge that I see is because of shuffling data across the network. Imagine an overly-simplified traditional star schema physical data model, like the one here:

If the data is distributed by the primary key of each table (the surrogate key), we are going to have a very nice (mostly) equal distribution of data across each node. This is good, at face value, because it means processing will be about the same on each node. We don't have skew (skew means data is not equally distributed, which means one node may be processing long after the processing on the other nodes is complete). The way data distribution (almost always) works is that a hash is done on the key, and a mod is applied based on the number of nodes in the cluster. For the sake of this conversation, we'll make it even more simplified, by imagining that we're distributing by the last number of the surrogate key, so all the values that end in "1" are stored on one node, all the values that end in "2" are stored on another, and so on. For the sake of this discussion, and to keep things clean, we can pretend our distributed RDBMS cluster has ten nodes, so we have (roughly) an equal amount of data on each of those nodes.
Now, imagine we need to join data between our TRANSACTION_F fact table, our CUSTOMER_D dimension table, and our PRODUCT_D dimension table. The fact table has a degenerate dimension surrogate key on it, and it's distributed based on that key. All the "1s" are on node 1, and so on. What happens when the fact table has a surrogate of "9001" and a customer surrogate key of "1234"? We've retrieved the relevant data from node 1, and then we join it to the data from node 4 to get the corresponding customer information. The product surrogate key corresponding to this transaction is "876", so the data corresponding to the product we care about is on node 6. Now, data needs to be shuffled from node to node in order to make those joins, and that shuffling is a performance killer.
There are ways to model this slightly differently, and it will make a bigger difference to performance than probably anything else you can do. This is a non-issue when we're leveraging traditional RDBMS on a single server, since there isn't the same network overhead associated with shuffling. While discussing those data distribution techniques are beyond the scope of this post, it is worth mentioning here, nonetheless. The bigger point here is that assuming that we understand the techniques for data distribution that allows us to minimize shuffling, we now have more storage and more compute, and our system far outperforms our outdated single-server approach, but to be sure: it is not a lift-and-shift to migrate from a single-server RDBMS to a distributed RDBMS system, and if that is the approach that is taken, you will be very disappointed with the results.
So where does that leave us with regard to distributed RDBMS and MPP systems? We understand the distribution techniques, and we've adjusted our model accordingly, but we continue to have the glaring issue of tight coupling. Again, once we run out of disk to store our data, we add more nodes, and with it we pay for additional compute. If we don't consistently need all of that compute (and you never do, because compute is never consistently above 90%), we're essentially throwing money away. If we add nodes to address peak computational needs, we end up paying for idle compute for the majority of the year (or day, as the case may be; many organizations have peak compute needs during normal business hours or during overnight ETL cycles, but we are paying for that compute 24 hours a day anyway).
What about Hadoop? Doesn't that solve my problems? No, it doesn't. But it's a start. In and of itself, Hadoop can be leveraged as a less expensive alternative to a distributed RDBMS. It doesn't have the RDBMS to manage the data, but the data can be stored relationally. However, my problem with Hadoop is that (often) people use HDFS as persistent storage, which creates the same problem for the exact same reasons discussed above. Leveraging HDFS as persistent storage is tightly coupling compute and storage, just as it was in our single-server RDBMS and just as it was with our distributed RDBMS.
If you want to truly get "infinite" scalability, you first have to accept that you must decouple your compute and storage. This adds a degree of complexity, but it is the key to scalability, and it's the secret to exploiting the pay-for-what-you-use cloud model. Leverage inexpensive disk for data storage, and bi-directionally scalable compute for your computational needs.
I'm going to hand-wave over some of the complexities and keep this somewhat high-level, but in modern AWS architectures in which you have a lot of data that you want to leverage for data science, data visualization and analytics, for instance, one common approach is to use S3 for storage ($13/compressed terabyte/month) and spin up EMR clusters for compute, where you can provision them to be right sized for your computational needs, or even provision multiple clusters at once and segregate your workloads accordingly, and terminate (or downsize) them when your computational requirements decrease.
What does this have to do with RDBMS? Well, for one thing, we talked earlier about how important SQL is in an architecture that traditionally leverages RDBMS (both distributed and single-server). In our Hadoop setting, where we've now decoupled our compute and storage, we can still organize our data relationally, even sans-RDBMS. Further, we can add an application to our cluster(s) to act as a distributed SQL engine, like Presto, which can also be leveraged as the back-end distributed SQL engine for our data visualization application that prefers RDBMS-type functionality and SQL capabilities.
The image below extends the previous image, now with decoupled storage in S3 and leveraging multiple EMR (Hadoop) clusters and Presto as the distributed SQL engine, used for analytics and data science.
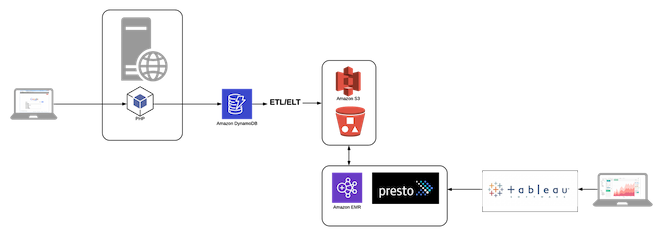
Now, we have the best of all worlds, as it applies to our data storage and associated compute. We have correctly positioned our document datastore as a back-end to our web application, so we can keep selling widgets, while dynamically scaling in and scaling out, with single-digit millisecond performance. Perhaps we've even done away with our compute server altogether (we've already forgone the "M" in the LAMP stack, we might as well do away with the "P", too) and perhaps opted for a FaaS architecture that leverages fully bi-directionally scalable Lambda functions. We still have relational database needs for our data science and analytics, but we avoided having to leverage a RDBMS there, too, by opting for storing data relationally but without an RDBMS with the decoupled S3/EMR (Presto) approach. Our data visualization application continues to lean on SQL to extract the data it requires to serve up reports, our analysts continue to leverage SQL (or HiveQL) to perform data exploration and analysis, and our ETL folks can leverage the application or language of their choice (such as Apache Spark), without the limitations of a declarative language (e.g. pipeline parallelism, code reusability, etc.), and with each technology choice, we're optimizing for both scale and cost.
The image here extends the previous image, now with serverless compute (Lambda) a static web server (S3), Apache Spark as an ETL/data integration application, and including SQL, HiveQL, and Python as additional languages (amongst anything else) to access the data for analytics and data science.

In my previous post, I talked about how we don't have an RDBMS system in the architecture, which is accurate, but that doesn't mean that we don't leverage relational databases. Far from it. I believe that proper curation, care and organization of data is more important in the world of "big data" than it ever was before, in part because we have so much more of it. What we do focus on is correctly positioning each technology, always focusing on bi-directional scalability, and always exploiting the pricing model that the cloud affords us.
