 Me
Metl;dr FaaS architectures do not replace everything else, and while they do allow us an inexpensive and fully scalable approach to do amazing things, we always always always want to position each and every one of our technologies correctly in the overall ecosystem. This post attempts to differentiate between where we might use a FaaS approach compared to a traditional batch processing approach, using natively distributed languages and technologies.
I've written somewhat extensively about my passions for serverless, microservices and Function as a Service architectures (FaaS), and some of the feedback I've received reminds me that I'm omitting a large group of folks that I consider myself to be a part of: big data analytics, so I wanted to take the time to differentiate between positioning FaaS, et. al, and big data analytics, as there are absolutely places (and room) for each.
While this post is not focused on FaaS architectures, it is important to recognize, even at a (very) high-level, what I'm talking about with regard to this topic. FaaS architectures take advantage of very small units of compute, and they can be applied to doing relatively fast stateless computations, with high degrees of concurrency. Further, there is no need to provision or manage the hardware for these stateless computations.
We use FaaS functions to do everything from rendering the data behind visualizations in a website to signing users in, to provisioning ephemeral hardware to sending email and text notifications. We subscribe to an architectural approach in which functions often publish messages to a queue (or topic, in the case of AWS SNS), and other functions fire upon receipt of those messages, as one common example.
Big data engineers and architects might quickly dismiss this architectural approach because their data is simply too large to be processed using this approach, and that is often correct. The table below, taken in part from the AWS Lambda limits page shows some of the restrictions to this type of compute:
| Function memory allocation | 128 MB to 3,008 MB, in 64 MB increments. |
| Function timeout | 900 seconds (15 minutes) |
| Invocation payload (request and response) | 6 MB (synchronous), 256 KB (asynchronous) |
| /tmp directory storage | 512 MB |
To be sure, Lambda functions can execute in parallel, but because they are independent and completely stateless, one function knows nothing about the others that may be executing. They are more like individual programs that happen to run at the same time than they are parallel processing in which something is managing the overall choreography of all executions, such as is the case with a technology like Apache Spark. It is true that we could accomplish Map/Reduce functionality using Lambda, that feels like a more academic exercise than a practical one, especially with so many tools and technologies out there that do it for us; many of them open source. Thus, I consider Lambda parallelism to be concurrent compute executions, and differentiate it from the type of parallel processing often used for things like distributed batch processing.
Imagine, if you will, that we're processing clickstream data, which is always "big", especially if your site or application is popular. If we were to be required to, say, generate a report that provides the median session time by day, we have a problem that cannot be solved additively. In order to determine median times, we have to process all the data for a given day. Sure, there are algorithmic ways to determine approximate median (beyond the scope of this post, but well worth the research, as it is often accurate enough to meet your needs at a fraction of the cost), but for the purposes of discussion here, we can imagine that we need the true median. We can't do this with a single Lambda function, because the data is too large and because the time it will take to process all of that data is beyond the timeout limitations that a single function call will allow.
As a sidenote, additive metrics are often good candidates for FaaS approaches. We simply consume the new data (perhaps, data having arrived in the last n seconds), sum it, retrieve the existing sum value of the metric, and add the two values together, producing a new current value.
In our clickstream example here, our data volumes are too unwieldy for a FaaS approach, but non-additive type metrics are surely not the only use-case for traditional batch processing (or streaming processing; a topic to be discussed in greater detail in a future post). Perhaps we have nightly ETL processes, which consume large volumes of data, cleanse, curate, integrate, validate, and persist it to, say, a file system or MPP/distributed RDBMS. This is a very common approach, which I am going to speak in some detail about here.
I believe in a data lifecycle in which the raw, unadulterated data is stored in perpetuity, in its original state. This enables an organization to be able to replay history, which is an incredibly powerful approach. While it is more costly, because you are storing large quantities of data, if anything ever goes wrong (and it will), such as incorrect code, accidental data deletion, or simply wanting to adjust logic and apply it to history, the data is there. While there is an additional cost, the storage costs are surprisingly small, because the cost of disk is quickly approaching zero. You could, for instance, store this raw data in something like AWS S3 Glacier at a cost of $0.004 per GB/Month, which is easily justifiable for the benefits and safety net it provides. You can usually do this processing leveraging a FaaS approach, because you are simply accumulating data at that point, and not transforming it in any way.
That raw data persisted to disk potentially includes Personally Identifiable Information, or PII, so you must be careful with security, which can be accomplished relatively simply using any number of approaches, such as AWS IAM, and it should go without saying that all data at rest and in-transit should be encrypted. Resources (including service users) with the correct permissions can then obfuscate, cleanse, curate and model the data accordingly, potentially in batch, and set the organized data down again, as illustrated below:
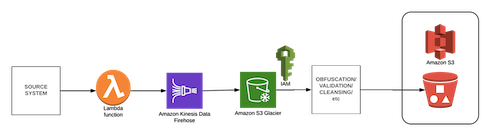
You may note that I also included Firehose in the image above, which can be used to manage periodic writes to S3/Glacier (say, every 5 or 15 minutes; configurable) so as to not try and use an object store or file system transactionally.
Now, we have our data in its original state, and with it, total and complete recoverability and replay-ability, and we've done some light cleansing, such as necessary data obfuscation, perhaps some basic modeling, validation, light data curation and the like, but that data isn't necessarily integrated with the rest of our data, which our Data Scientists and Analysts will certainly want and need.
At this point, we're accumulating a lot of data, and we may not necessarily be able to (or need to) process that in real-time, or with a FaaS architecture. Perhaps we have an overnight ETL process, for instance, that integrates our days data in bulk. This is common; oftentimes the data would prove to be mis-leading or confusing if it were aggregated and summarized in mini-batch (for instance, day over day sales would be alarming if someone were to look at the information at noon), or perhaps Analysts would struggle to explain data that is changing out from under them, as it is updated intra-day.
Processing this type of data (large volumes, in batch) is a perfect use case for technologies such as Hadoop, whereas it is not a great candidate for something like a FaaS architecture. Further, this batch processing can leverage technologies built for this type of processing, such as Map/Reduce or more recent offerings, such as Apache Spark. To be clear, Spark offers streaming (micro-batch) capabilities, but as I mentioned previously, streaming architectures are a topic for another day.
Spark is a great application for bulk processing, and is far superior than traditional Map/Reduce in a number of ways, not limited to its usage of memory, its use of Directed Acyclic Graphs, which are both big reasons as to why Spark can claim 100 times or more faster processing compared to traditional Map/Reduce. Additionally, it also offers a BYO programming language approach, so users can leverage the Spark framework while writing their code using popular languages like Python, SQL, Scala, Java, or R. Leveraging a language like Python, for instance, allows for superior code reuse compared to a declarative language like SQL, which can further add to the robustness of your data integration system, while SQL users (those writing reports or performing data exploration) can continue to access data in a language they are comfortable using, but while taking advantage of the superior Spark execution engine.
I've updated the previous image to now include Spark as the data integration application, both for the initial obfuscation step, as well as meeting the larger (in our example, nightly) ETL step, in which the data is properly modeled and integrated with other data in the system. Additionally, I've added a commercial distributed SQL MPP to the mix, writing this data to Snowflake, although any number of other offerings can be leveraged in its place, such as AWS Redshift, Apache Presto and GPC BigQuery:

We can now hook up our favorite data visualization application, such as Tableau or Looker, while taking advantage of the compute in (in this case) Snowflake. I've updated the running image with Tableau, and also added multiple access points for our Data Scientists and Analysts, with various applications, such as Python, R (via the dplyr package), HiveQL, and SQL:

Now we have access to data in various locations (and in various states), between S3 and Snowflake, and with the technologies best positioned to do the work. We aren't necessarily asking Data Scientists to move from Python to R (or vice-versa), we can leverage distributed compute technologies (like HiveQL), classic analyst languages (like SQL), Spark, or seemingly anything else.
We can further continue to leverage FaaS approaches to do many interesting things, such as provisioning and terminating ephemeral compute, sending emails and alerts, integrating with third-party applications (like Slack, for instance), and a million other things. The point here is that while FaaS architectures may not fulfill all of our compute needs (in this case, because of data volumes and our batch processing that exceeds the time restrictions of Lambda functions), they do fulfill many requirements, at scale and at cost, and they can play a complimentary role to many others, like our traditional batch processing discussed here.
Once again, we've optimized our environment by always positioning technologies correctly. We've introduced some data lifecycle concepts (such as raw, unadulterated data persistence and the ability to replay history), while leveraging distributed technologies (like Apache Spark) over FaaS calls, we've added a MPP SQL engine (and mentioned a number of alternatives), and provided access for our Analysts and Data Scientists at multiple points in the data ecosystem, all while enabling them to use the technologies and tools they are most comfortable with. Finally, we discussed how the FaaS architecture continues to be leveraged; to be sure, these are not mutually exclusive approaches, but rather complimentary ones, which together can produce an incredibly robust, resilient overall data ecosystem.

